1 ConcurrentHashMap 的实现原理与使用
1.1 为什么要使用 ConcurrentHashMap
- 线程不安全的 HashMap ,在多线程下 HashMap 的 Entry 链表导致形成环形数据结构, Entry 的 next 节点永远不为空,就会产生死循环获取 Entry 。
- 效率低下的 HashTable ,使用 synchronized 保证线程安全。
- ConcurrentHashMap 的锁分段技术有效提升并发访问率。 HashTable 效率低下是因为所有访问 HashTable 的线程都必须竞争同一把锁,如果容器里
有多把锁,每把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程就不会存在锁竞争。
1.2 ConcurrentHashMap 的结构
ConcurrentHashMap 由 Segment 数组结构和 HashEntry 数组结构组成。 Segment 是一种可重入锁(ReentrantLock), Segment的结构和 HashMap
结构类似。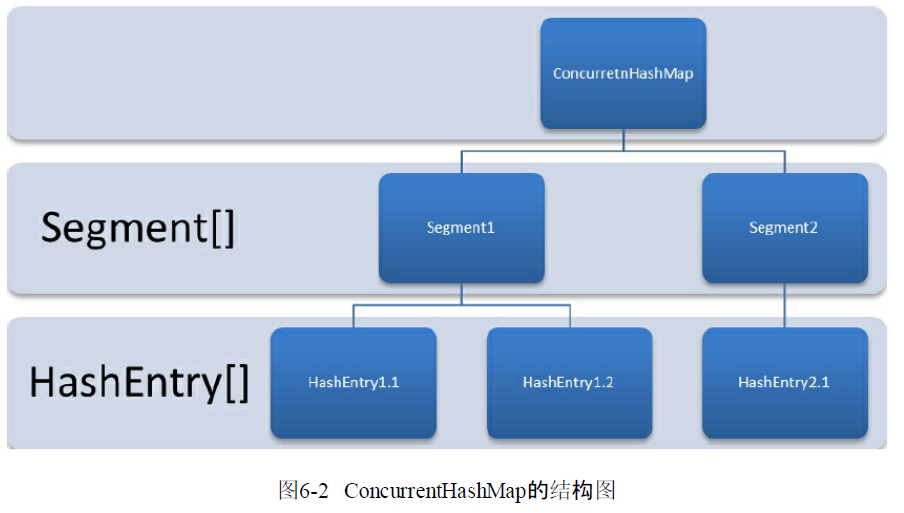
1.3 ConcurrentHashMap 的初始化
- 初始化 segments 数组
- 初始化 segmentShift 和 segmentMask。用于散列算法的一些值。
- 初始化每个 segment,包括容量以及负载因子。
1.4 ConcurrentHashMap 的操作
1.4.1 get 操作
get 操作的高效之处在于整个 get 过程不需要加锁,除非读到的值是空才会加锁重读。如何保证不加锁?原因在于它的 get 方法里将要使用的共享变量都
定义成 volatile 类型,如用于统计当前 Segment 大小的 count 字段和用于存储值的 HashEntry 的 value 。但只能被单线程写(有一种情况可以被
多线程写,就是写入的值不依赖于原值),在 get 操作里只需要读不需要写共享变量 count 和 value ,所以不需要加锁。即使两个线程同时修改和获取
volatile 变量, get 操作也能拿到最新的值,这是用 volatile 替换锁的经典应用场景。
1.4.2 put 操作
必须加锁。先定位到 Segment ,然后在 Segment 里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对 Segment 里的 HashEntry 数组
进行扩容,第二步定位添加元素的位置,然后将其放在 HashEntry 数组里。
- 是否需要扩容:插入元素前会判断 Segment 里的 HashEntry 数组是否超过容量,如果超过阈值,则对数组进行扩容。
- 如何扩容:先创建一个容量是原来容量两倍的数组,然后将原数组里元素进行散列后插入到新的数组里。为了高效, 只会对某个 Segment 进行扩容。
1.4.3 size 操作
每个 Segment 的count 是 valatile 变量,但是累加过程中有可能 count 发生变化,最安全的做法是在统计 size 的时候把所有 Segment 的 put、
remove 和 clean 方法全部锁住,但是非常低效。所以 ConcurrentHashMap 的做法是尝试 2 次通过不锁住 Segment 的方式来统计累和,如果 count
发生变化,再采用加锁方式统计。如果判断count 发生变化呢?使用 modCount 变量。
2 ConcurrentLinkedQueue
实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。前者可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队
用不同的锁)等方式实现。非阻塞的实现则可以使用循环 CAS 的方式来实现。
2.1 ConcurrentLinkedQueue 的结构
由 head 节点和 tail 节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成。默认情况下 head 节点存储的元素为空,
tail 节点等于 head 节点。
2.2 入队列
2.2.1 入队列的过程
- 添加元素1。队列更新 head 节点的 next 节点为元素1节点,又因为 tail 节点默认情况下等于 head 节点,所以它们的 next 节点都指向元素1节点。
- 添加元素2。队列首先设置元素1节点的 next 节点为元素2节点,然后更新 tail 节点指向元素2节点。
- 添加元素3。设置 tail 节点的 next 节点为元素3节点。
- 添加元素4。设置元素3的 next 节点为元素4节点,然后将 tail 节点指向元素4节点。
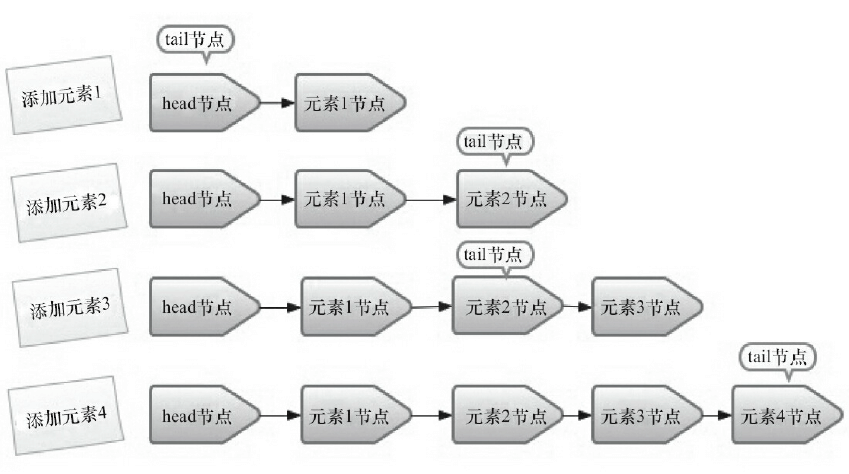
入队主要做两件事:一是将入队节点设置成当前队列尾节点的下一个节点;二是更新 tail 节点,如果 tail 节点的 next 节点不为空,则将入队节点设置成
tail 节点,如果 tail 节点的 next 节点为空,则将入队节点设置成 tail 的 next 节点,所以 tail 节点不总是尾节点。
在代码中,入队主要做两件事:一是定位出尾节点(通过 tail 的 next 是否为空);二是使用 CAS 算法将入队队列设置成尾节点的 next 节点,如不成功则重试。
(进行 tail 的 next 判断是否为空时,如果循环两次都不为空,则重新进行队列,因为肯定有别的线程加了尾)。源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public boolean offer(E e) {
if (e == null) throw new NullPointerException();
// 入队前,创建一个入队节点
Node<E> n = new Node<E>(e);
retry:
// 死循环,入队不成功反复入队。
for (;;) {
// 创建一个指向tail节点的引用
Node<E> t = tail;
// p用来表示队列的尾节点,默认情况下等于tail节点。
Node<E> p = t;
for (int hops = 0; ; hops++) {
// 获得p节点的下一个节点。
Node<E> next = succ(p);
// next节点不为空,说明p不是尾节点,需要更新p后在将它指向next节点
if (next != null) {
// 循环了两次及其以上,并且当前节点还是不等于尾节点
if (hops > HOPS && t != tail)
continue retry;
p = next;
}
// 如果p是尾节点,则设置p节点的next节点为入队节点。
else if (p.casNext(null, n)) {
/*如果tail节点有大于等于1个next节点,则将入队节点设置成tail节点,
更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点*/
if (hops >= HOPS)
casTail(t, n); // 更新tail节点,允许失败
return true;
}
// p有next节点,表示p的next节点是尾节点,则重新设置p节点
else {
p = succ(p);
}
}
}
}
2.2.2 定位尾节点
通过判断 tail 节点和 tail 节点的 next 节点。
2.2.3 HOPS 的设计意图
用如下实现是否可行:1
2
3
4
5
6
7
8
9
10
11public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
Node<E> n = new Node<E>(e);
for (;;) {
Node<E> t = tail;
if (t.casNext(null, n) && casTail(t, n)) {
return true;
}
}
}
让 tail 节点永远作为队列的尾节点,这样实现代码量非常少。但是有个缺点是,每次都要更新 tail 节点为尾节点,而使用 HOPS 常量,进行判断,如果
当 tail 节点和尾节点的距离大于等于常量 HOPS 的值(默认等于1)时才更新 tail 节点,来通过增加对 volatile 变量的读操作来减少对 volatile 变量
的写操作,入队效率提升。
2.3 出队列
只有当 head 节点里没有元素时,出队操作才会更新 head 节点。这种做法也是通过 hops 变量来减少使用 CAS 更新 head 节点的消耗,从而提高出队效率。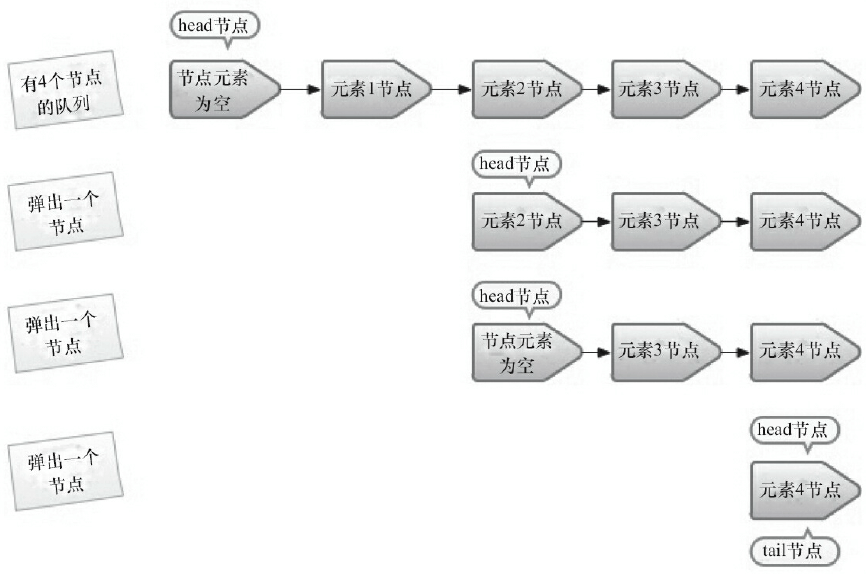
3 Java 中的阻塞队列
3.1 什么是阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
- 支持阻塞的插入方法:意思当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
3.2 Java 里的阻塞队列
| 类名 | 描述 |
|---|---|
| ArrayBlockingQueue | 一个由数组结构组成的有界阻塞队列 |
| LinkedBlockingQueue | 一个由链表结构组成的有界阻塞队列 |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 使用优先级队列实现的无界阻塞队列 |
| SynchronousQueue | 不存储元素的阻塞队列 |
| LinkedTransferQueue | 由链表结构组成的无界阻塞队列 |
| LinkedBlockingDeque | 由链表结构组成的双向阻塞队列 |
3.3 阻塞队列的实现原理
3.3.1 使用通知模式实现
即当生产者往满的队列里添加元素时会阻塞住消费者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
4 Fork/Join 框架
4.1 什么是 Fork/Join 框架
Fork 就是把一个大任务切分为若干子任务并行的执行, Join 就是合并这些子任务的执行结果。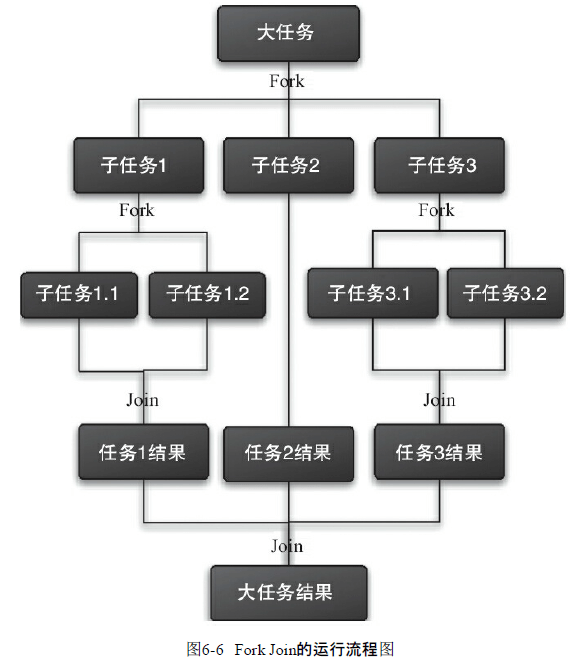
4.2 工作窃取算法
某个线程先把自己队列里的任务干完,而其它线程对应的队列里还有任务等待处理,这时候,完成任务的线程去做还有任务的线程的任务。
- 优点:充分利用线程进行并行计算,减少线程间的竞争。
- 缺点:如果只有一个任务时,还是会有竞争。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
4.3 Fork/Join 框架的设计
- 分割任务:首先我们需要由一个 fork 类来把大任务分割成小任务,有可能子任务还是很大,所以还需要不停地分割,直到分割出的子任务足够小。
- 执行任务并合并结果:分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,
启动一个线程从队列里里拿数据,然后合并这些数据。
Fork/Join 使用两个类来完成以上两件事。
- ForkJoinTask:我们要使用 ForkJoin框架,必须首先创建一个 Fork/Join 任务。它提供在任务中执行 fork() 和 join() 操作的机制。通常情况下,
我们只需要继承它的子类,而 Fork/Join 框架提供了以下两个子类。 RecursiveAction:用于没有返回结果的任务; RecursiveTask:用于有返回结果的任务。 - ForkJoinPool:ForkJoinTask 需要通过 ForkJoinPool 来执行:任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。
当一个工作线程的队列里暂时没有任务时,它会随机从其它工作线程的队列的尾部 获取一个任务。
4.4 使用 Fork/Join 框架
需求:计算1+2+3+4的结果。
如果希望每个子任务最多执行两个数的相加,我们设置分割的阈值是2,由于是4个数字相加,所以fork成两个子任务,一个计算1+2,一个计算3+4,然后再join两个子任务。
由于有结果的任务,因此继承 RecursiveTask。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public class CountTask extends RecursiveTask<Integer>{
private static final int THRESHOLD = 2; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
// 如果任务足够小就计算任务
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
CountTask task = new CountTask(1, 4);
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
4.5 Fork/Join 框架的实现原理
ForkJoinPool 由 ForkJoinTask 数组和 ForkJoinWorkerThread 数组组成, ForkJoinTask 数组负责将存放程序提交给 ForkJoinPool 的任务,
而 ForkJoinWorkerThread 数组负责执行这些任务。
4.5.1 ForkJoinTask 的 fork 方法实现原理
使用 push 方法,把当前任务存放在 ForkJoinTask 数组队列中,再调用 ForkJoinPool 的 signalWork() 方法唤醒或创建一个工作线程来异步的执行这个任务,
然后立即返回结果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
}
else if (n >= m)
growArray();
}
}
4.5.2 ForkJoinTask 的 join 方法实现原理
Join 方法主要用于阻塞当前线程并等待获取结果。调用 doJoin() 方法,通过查看任务状态,如果执行完则直接返回任务状态;如果没执行完,
则从任务数组里取出任务并执行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private void reportException(int s) {
if (s == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL)
rethrow(getThrowableException());
}
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}