索引能够轻易将查询性能提高几个数量级,“最优”的索引有时比一个“好的”索引性能要好两个数量级。创建一个真正“最优”的索引经常需要重写查询。
1 索引基础
1.1 索引的类型
在 MySQL 中,索引是在存储引擎层而不是服务器层实现的。所以,并没有统一的索引标准。即使多个存储引擎支持同一种类型的索引,其底层的事先也可能不同。
1. B-Tree 索引
InnoDB 本质是“B+Tree”。假设有如下数据表:
1 | CREATE TABLE People( |
对于表中的每一行数据,索引中包含了 last_name、first_name和 dob 列的值,下图显示了该索引是如何组织数据的存储的:
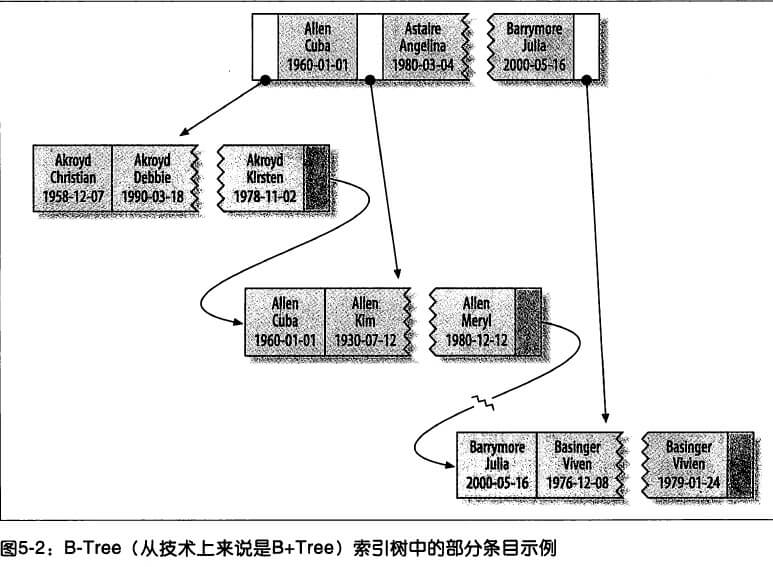
注:索引对多个值进行排序的依据是CREATE TABLE语句中定义索引时列的顺序。
- 全值匹配:指和索引中的所有列进行匹配。
- 匹配最左前缀:前面提到的索引可用于查询所有姓为 Allen 的人,即只使用索引的第一列。
- 匹配列前缀:例如查找所有以 J 开头的姓的人。这里也只使用了索引的第一列。
- 匹配范围值:例如查找姓在 Allen 和 Barrymore 之间的人。
- 精确匹配某一列并范围匹配另外一列:查找所有姓为 Allen,并且名字是字母 K 开头的人。即第一列 last_name 全匹配,第二列 first_name 范围匹配。
- 只访问索引的查询
因为索引树的节点是有序的,所以除了按值查找之外,索引还可以用于查询中的ORDER BY操作(按顺序查找)。一般来说,如果 B-Tree 可以按照某种方式查找到值,那么也可以按照这种方式用于排序。所以如果ORDER BY子句满足前面列出的几种查询类型,则这个索引也可以满足对应的排序需求。
下面是一些关于 B-Tree 索引的限制:
- 如果不是按照索引的最左列开始查找,则无法使用索引。例,上面的例子的索引无法查找名字为 Bill 的人,也无法查找某个特定生日的人,因为这两列都不是最左数据列。类似地,也无法查找姓氏以某个字母结尾的人。这是关于
like '%关键字'的知乎讨论:https://www.zhihu.com/question/52718330?sort=created - 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查询。
有些限制并不是 B-Tree 本身导致的,而是 MySQL 优化器和存储引擎使用索引的方式导致的,这部分限制在未来的版本中可能就不再是限制了。
2. 哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况这一点对性能的影响并不明显。
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
- 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。例,在(A,B)建立哈希索引,如果查询只有 A ,则无法使用该索引。
- 访问哈希索引的数据非常快,除非有很多哈希冲突。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针。
当字段过大,例如存储 URL 时,可以额外使用一个列,用于存储该列的哈希,用于排序。但为了避免哈希冲突的问题,需要where url = 'http://www.mysql.com' AND url_crc=CRC32('http://www.mysql.com'),这样的性能会非常高。(可以使用触发器来自身插入哈希列)。
3. 空间数据索引(R-Tree)
MyISAM 表支持空间索引。
4. 全文索引
使用MATCH AGAINST操作,而不是普通的WHERE。
2 索引的优点
最常见的 B-Tree 索引,按照顺序存储数据,所以 MySQL 可以用来做 ORDER BY 和 GROUP BY 操作。因为数据时有序的,所以 B-Tree 也就会将相关的列值都存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询:
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变为顺序 I/O。
对于中到大型表,索引就非常有效。但对于特大型表,需要技术直接区分出查询需要的一组数据,而不是一条记录一条记录地匹配,例,分区技术:建立元数据信息表,例,假如执行那些需要聚合多个应用分布在多个表的数据的查询,则需要记录“哪个用户的信息存储在哪个表中”的元数据,这样在查询时就可以直接忽略那些不包含指定用户信息的表。对于 TB 级别的数据,定位单条记录的意义不大,所以经常会使用块级别元数据技术来替代索引。
3 高性能索引的索引策略
3.1 前缀索引和索引选择性
索引选择性:不重复的索引值/数据表的记录总数,范围在0~1间,越高则查询越快。唯一索引的选择性是1,性能也是最好的。
列值过长,可以使用部分字段LEFT(city,3)作为前缀索引,这个值是通过COUNT(DISTINCT LEFT(city,5))/COUNT(*)的值来决定的,结果在 0.031 基本上就可用了。接着创建:ALTER TABLE sakila.city_demo ADD KEY(city(5));
但是前缀索引虽然使索引更小、更快,但是无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
后缀索引(suffix index)也很有用途(电子邮箱),可以使用字符串反转后存储。
3.2 多列索引
为每个列创建独立的索引,从SHOW CREATE TABLE中很容易看到这种情况:
1 | CREATE TABLE t( |
这种索引策略是由于“把 WHERE 条件里面的列都建上索引”这样模糊的建议导致的。这最多是“一星”索引。例,WHERE c1 = '1' OR c2 = '2',虽然在 MySQL5.0+ 会优化使用这两个索引,但是在 explain 的 extra 中会有 Using union,因此说明了索引的糟糕:
- 出现多个
AND条件,则需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。 - 多个
OR或者联合操作时,如果有些索引的选择性不高,需要合并扫描返回的大量数据。 - 如果在
EXPLAIN中看到有索引合并,应该好好检查查询和表的结构,也可以通过参数optimizer_switch来关闭索引合并功能,也可以使用IGNORE INDEX提示让优化器忽略掉某些索引。
3.3 选择合适的索引列顺序
最好通过 pt-query-digest 这样的工具报告重提取“最差”查询,再按照索引顺序进行优化。如果没有类似的具体查询来运行,那么最好还是按照经验法则来做,因为经验法则考虑的是全局性和选择性,而不是某个具体查询: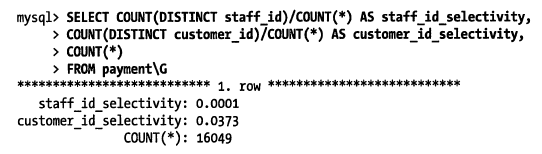
customer_id 的选择性更高,所以答案是将其作为索引列的第一列。
3.4 覆盖索引
如果一个索引包含(覆盖)所有需要查询的字段的值,我们就称为“覆盖索引”。
- 因为索引是按照列值顺序存储的,所以对于 I/O 密集型的范围查询会比随机从磁盘读取每一行数据的 I/O 要少得多。
- 并不是所有类型的索引都可以称为覆盖索引。覆盖索引必须要存储索引列的值。
当发起一个被覆盖的查询,在 EXPLAIN 的 Extra 列可以看到 Using index 的信息。
type列的index和Extra列的Using index是完全不同,前者和覆盖索引毫无关系,它只是表示这个查询访问数据的方式。
索引覆盖查询还有很多陷阱可能导致无法实现优化: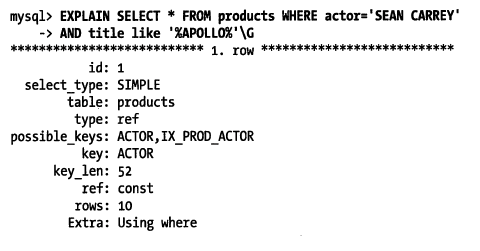
- 没有任何索引能够覆盖这个查询。因为查询从表中选择了所有的列,而没有任何索引覆盖了所有的列。
- MySQL 不能再索引中执行
LIKE操作,MySQL5.5- 只允许在索引中做简单比较操作,MySQL 能在索引中做最左前缀匹配的LIKE查询,因为该操作可以转为简单的比较操作,但是如果是通配符开头的LIKE查询,存储引擎就无法做比较匹配。这种情况下,MySQL 服务器只能提取数据行的值,而不是索引值来做比较。
也有办法解决上面说的两个问题,重写查询并巧妙地设计索引。先将索引扩展至三个数据列(artist,title,prod_id),然后按如下方式重写查询:
3.5 使用索引扫描来做排序
MySQL 有两种方式可以生成有序的结果:通过排序操作;或按索引顺序扫描;如果 EXPLAIN 出来的 type 列的值为 “index”,则说明 MySQL 使用了索引扫描来做排序(不要和 Extra 列的 “Using index” 搞混淆了)。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那就不得不每扫描一条索引记录就回表查询一次对应的行。这基本上都是随机 I/O,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢。
如果查询需要关联多张表,则只有当 ORDER BY 子句引用的字段全部为第一个表时,才能使用索引做排序。
例:
1 | CREATE TABLE rental( |
WHERE rental_date = '2015-05-25' ORDER BY inventory_id, customer_id 因为索引第一列被指定为一个常数,所以查询排序。WHERE rental_date = '2015-05-25' ORDER BY inventory_id 也可以使用查询排序。WHERE rental_date > '2005-05-25 ORDER BY rental_date, inventory_id 也可以。
下面是不能使用索引做排序的查询:
WHERE rental_date = '2015-05-25' ORDER BY inventory_id DESC, customer_id ASC;因为索引列都是正序排序。WHERE rental_date = '2015-05-25' ORDER BY inventory_id, staff_id;因为引用了一个不再索引中的列。WHERE rental_date = '2015-05-25' ORDER BY customer_id;无法组成索引的最左前缀。WHERE rental_date > '2015-05-25' ORDER BY inventory_id, customer_id;因为第一列上是范围条件。WHERE rental_date = '2015-05-25' AND inventory_id IN (1,2) ORDER BY customer_id;还是范围查询。