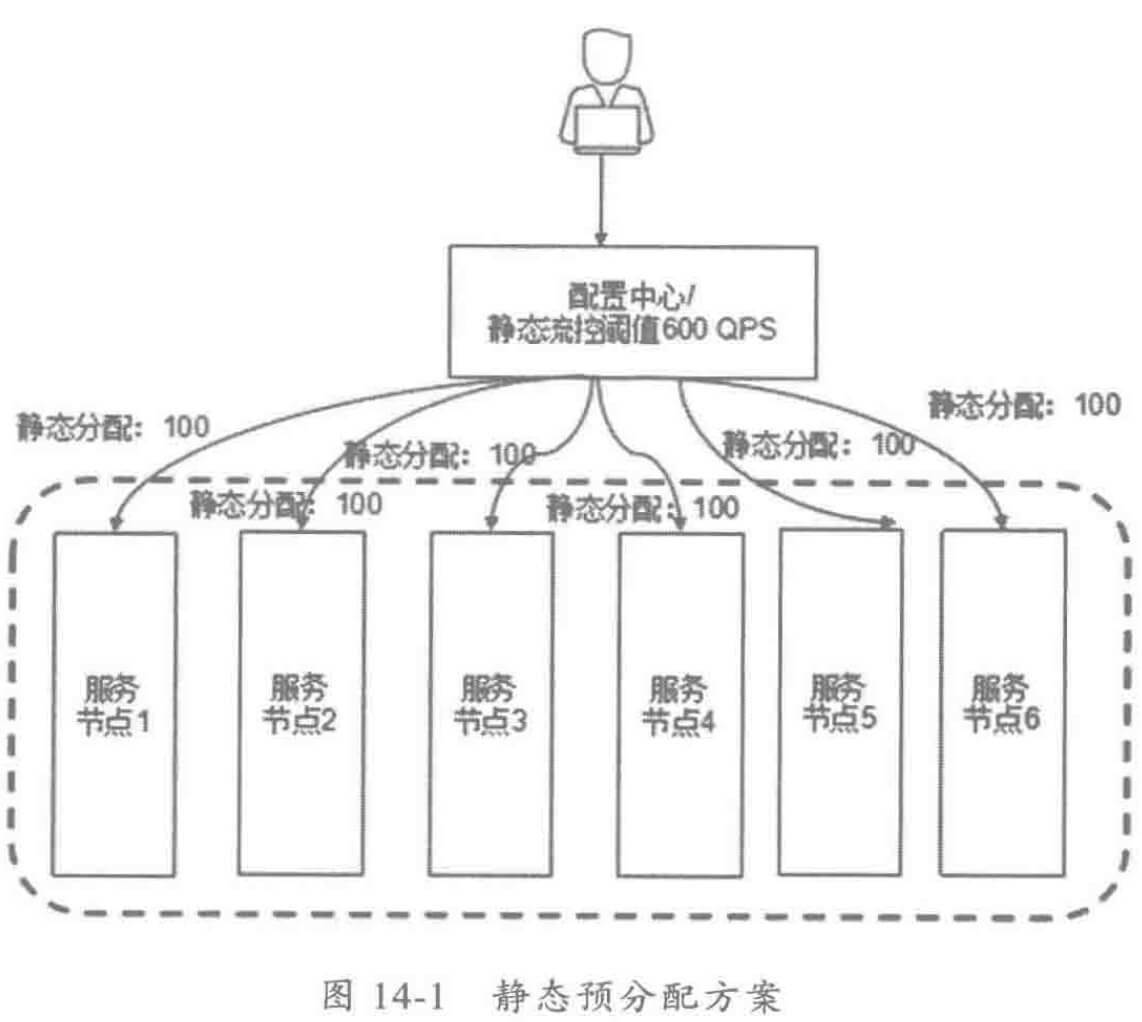
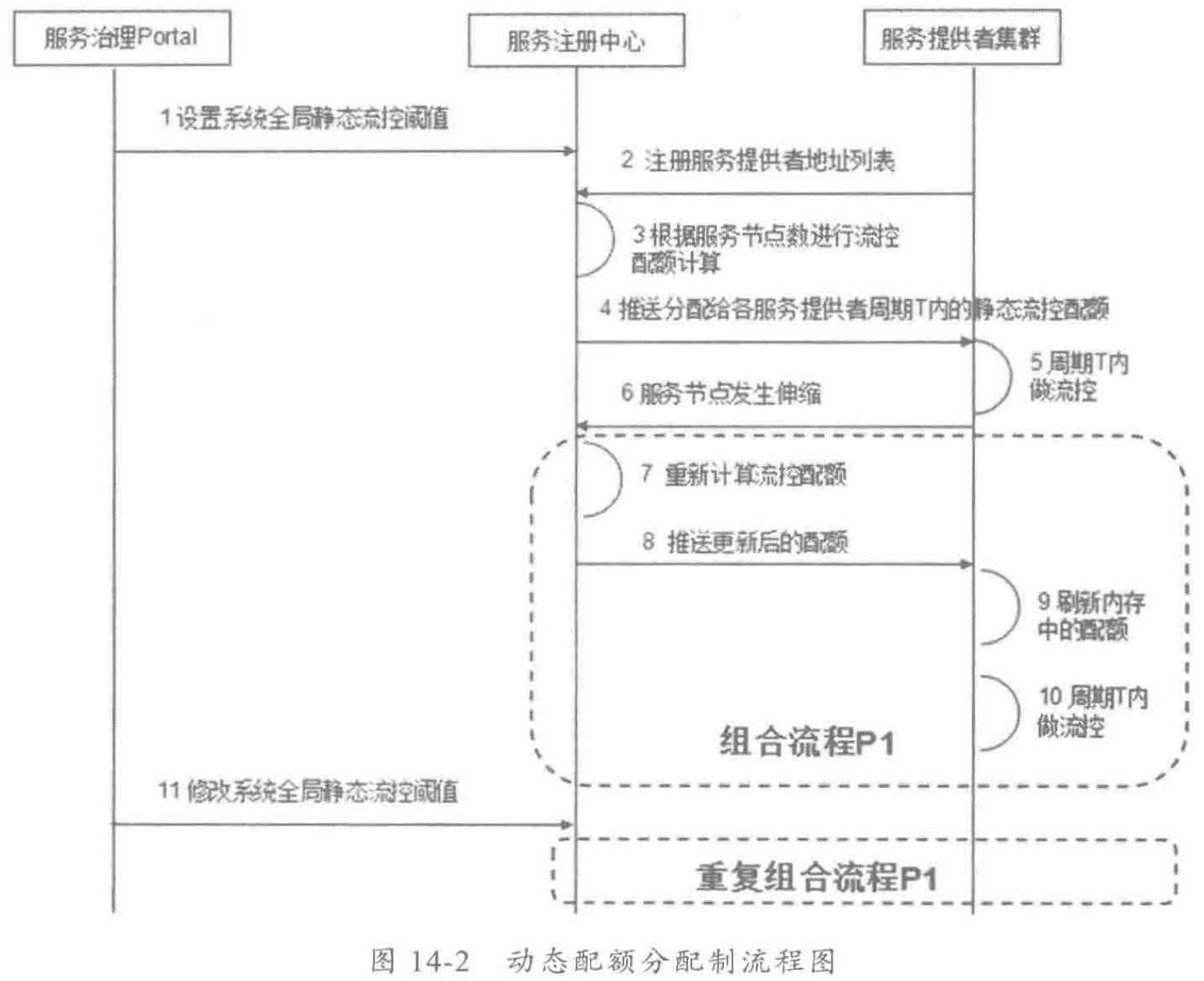
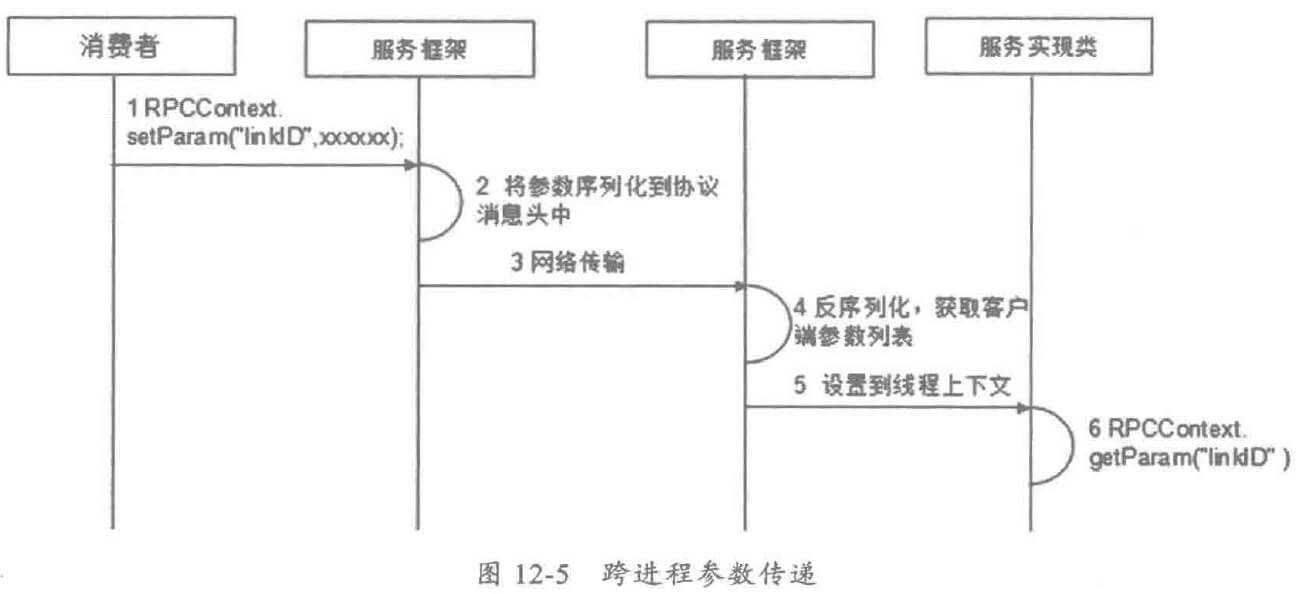
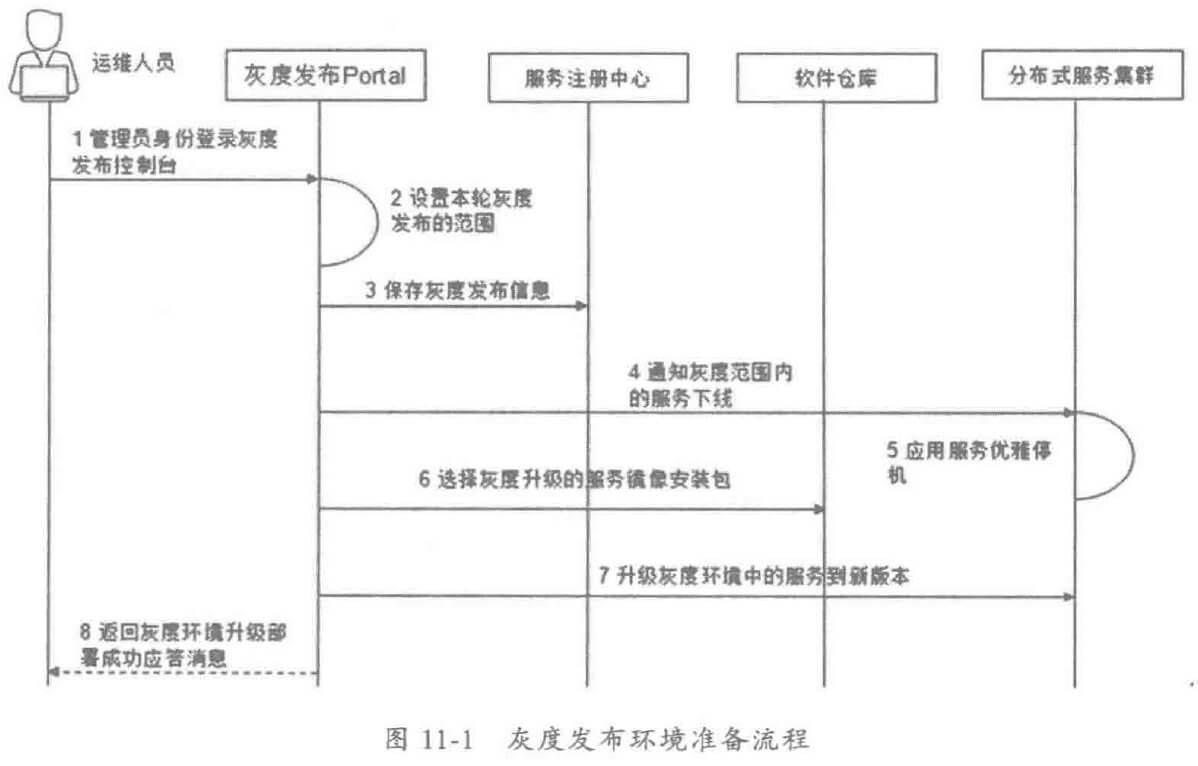
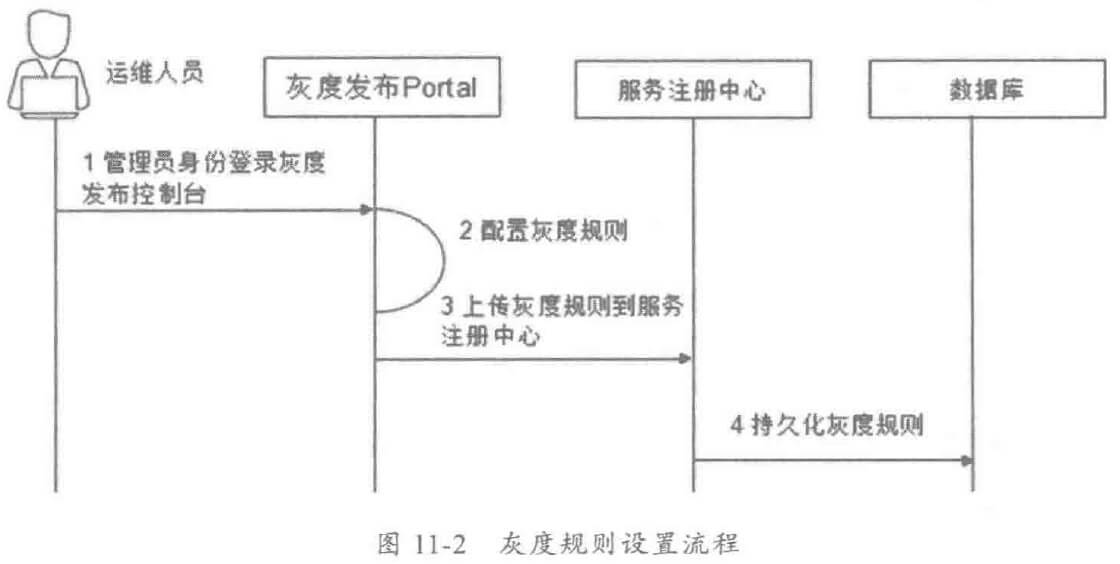
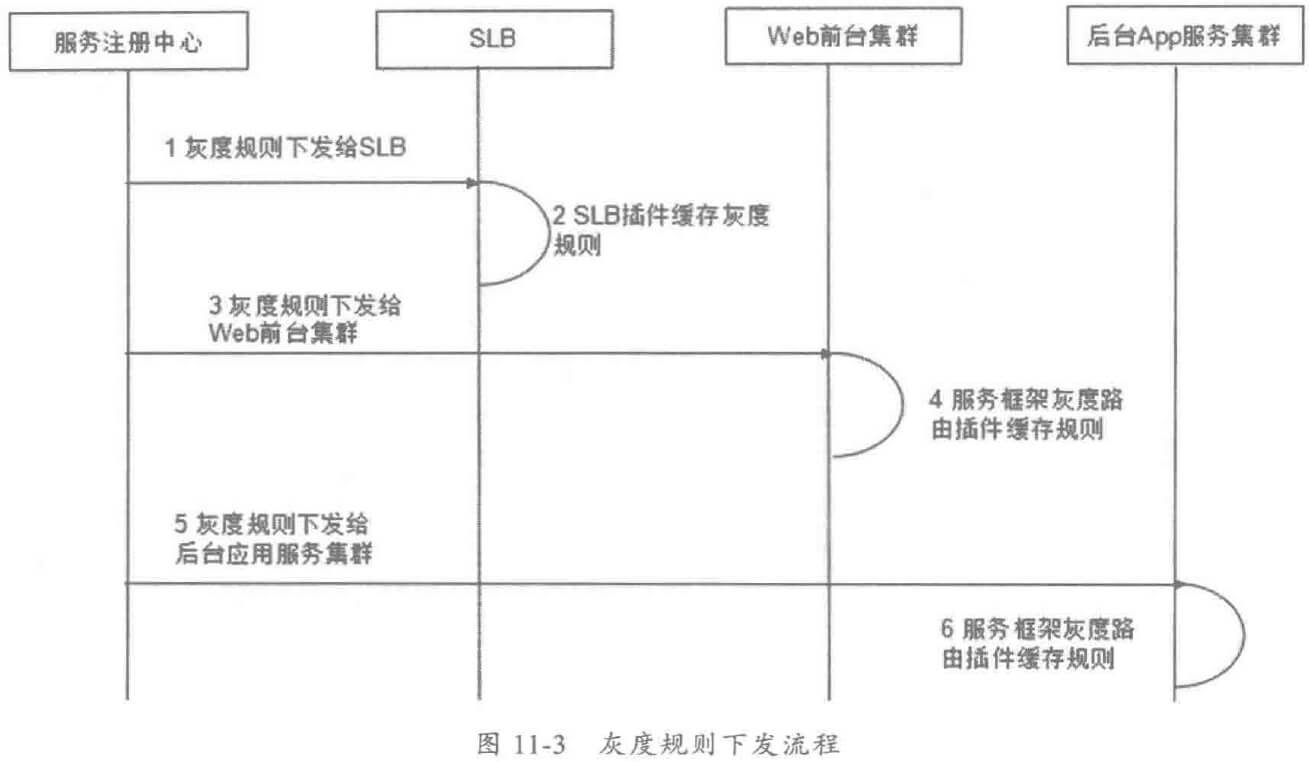
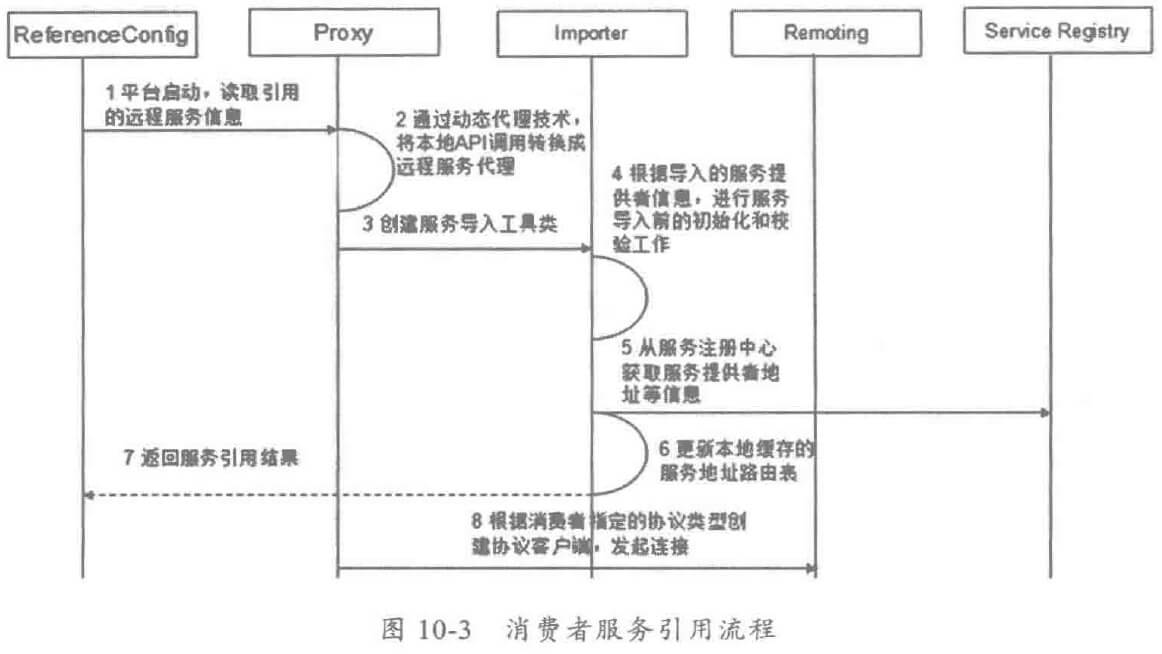
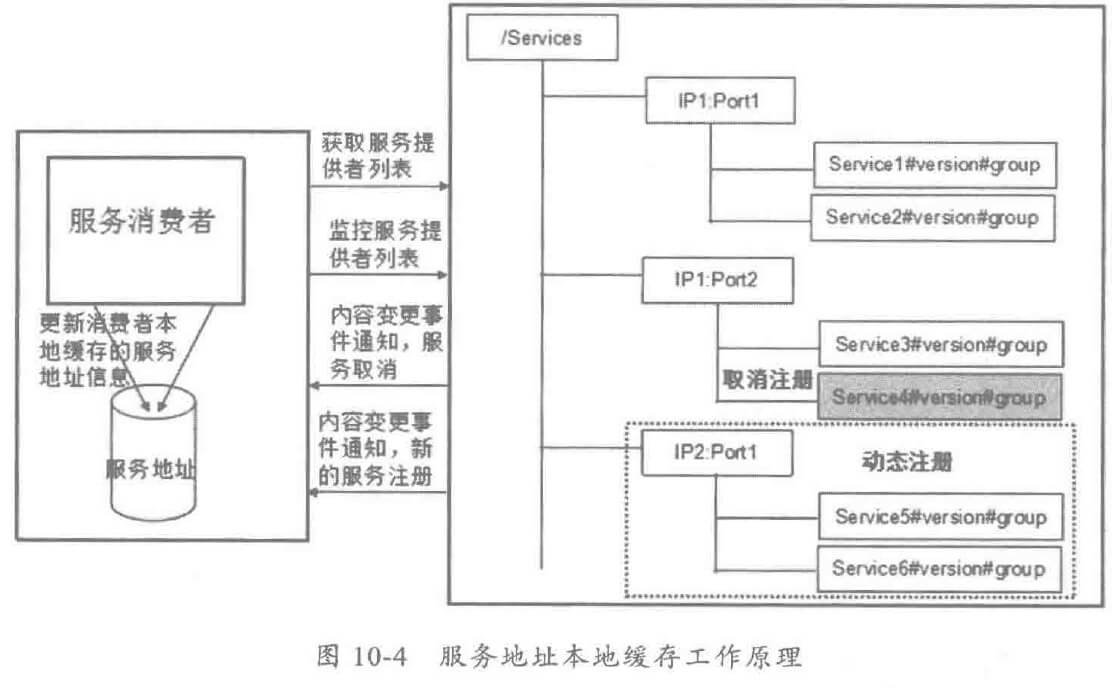
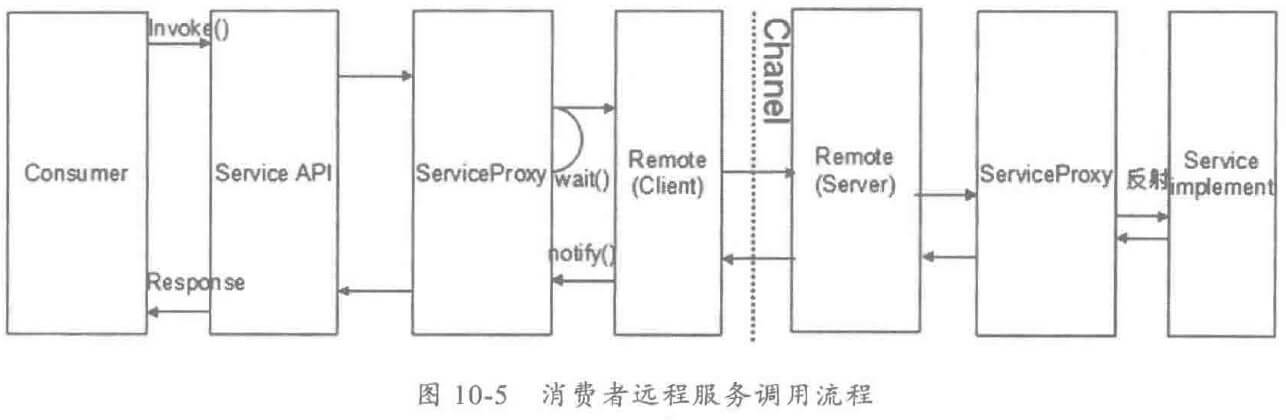
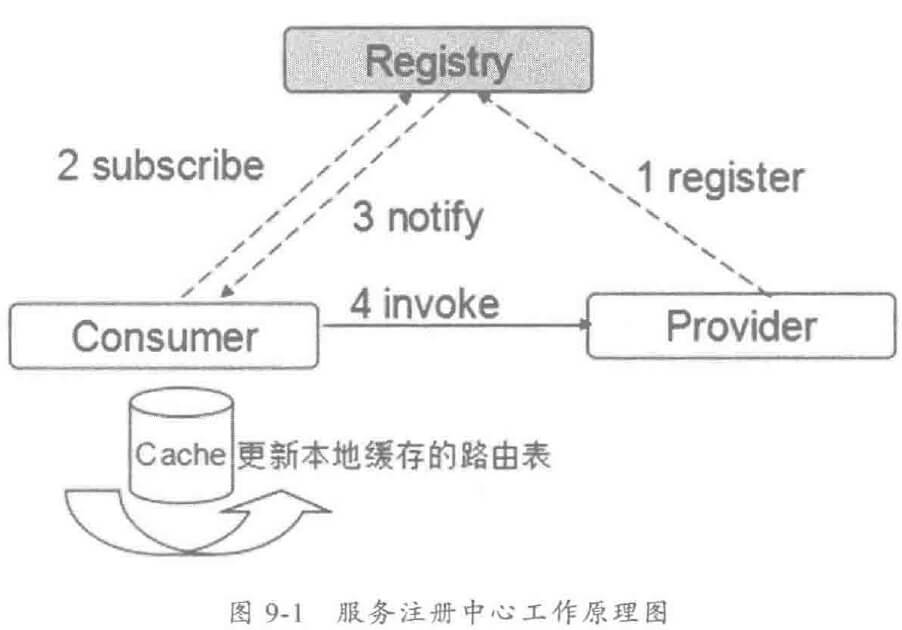
随着业务发展,服务越来越多,如何协调线上运行的各个服务,保障服务的 SLA,以及小服务资源浪费的问题,需要能够基于服务调用的性能 KPI数据进行容量管理,合理分配各个服务的资源占用。
线上业务发生故障,需要对故障业务做服务降级、流量控制,快速恢复业务。
为了满足服务线下管控、保障线上高效运行,需要有一个统一的服务治理框架对服务进行统一、有效管控,保障服务的高效、健康运行。
1 服务治理技术的历史变迁
- 第一代服务治理 SOA Governance:以 IBM为首的 SOA解决方案提供商推出的针对企业 IT系统的服务治理框架,它主要聚焦在对企业 IT系统中异构服务的质量管理、服务发布审批流程管理和服务建模、开发、测试以及运行的全生命周期管理。
- 第二代以分布式服务框架为中心的服务治理:随着电商和移动互联网的快速发展,以阿里为首的基于同一分布式服务框架的全新服务治理理念诞生,它聚焦于对内部同构服务的线上治理,保障线上服务的运行质量。相对比传统 IT架构的服务治理,由于服务的开发模式、部署规模、组网类型、业务特点等差异巨大,因此服务治理的重点也从线下转移到了线上服务质量保障。
- 微服务架构+云端服务治理:2013年至今,随着云计算和微服务架构的发展,以 AWS为首的基于微服务架构+云服务化的云端服务治理体系诞生,它的核心理念是服务微自治,利用云调度的弹性和敏捷,逐渐消除人工治理。
微服务架构可以实现服务一定程度的自治,例如服务独立打包、独立部署、独立升级和独立扩容。通过云计算的弹性伸缩、单点故障迁移、服务健康度管理和自动容量规划等措施,结合微服务治理,逐步实现微服务的自治。
1.1 SOA Governance
SOA Governance的定位:面向企业 IT系统异构服务的治理和服务生命周期管理,它治理的服务通常是 SOA服务。
传统的 SOA Governance包含以下四部分内容:
- 服务建模:验证功能需求与业务需求,发现和评估当前服务,服务建模和性能需求,开发治理规范。
- 服务组装:创建服务更新计划,创建和修改服务以满足所有业务需求,根据治理策略评估服务,批准组装完成。
- 服务部署:确保服务的质量,措施包括功能测试、性能测试和满足度测试,批准服务部署。
- 服务管理:在整个生命周期内管理和监控服务,跟踪服务注册表中的服务,根据 SLA上报服务的性能 KPI数据进行服务质量管理。
SOA Governance 工作原理如下:
传统 SOA Governance 缺点如下:
- 分布式服务框架的发展,内部服务框架需要统一,服务治理也需要适应新的架构,能够由表及里,对服务进行细粒度的管控。
- 微服务架构的发展和业务规模的扩大,导致服务规模量变引起质变,服务治理的特点和难点也随之发生变化。
- 缺少服务运行时动态治理能力,面对突发的流量高峰和业务冲击,传统的服务治理在响应速度、故障快速恢复等方面存在不足,无法更敏捷地应对业务需求。
1.2 分布式服务框架服务治理
- 分布式服务矿机的服务治理定位:面向互联网业务的服务治理,聚焦在对内部采用统一服务框架服务化的业务运行态、细粒度的敏捷治理体系。
- 治理的对象:基于统一分布式服务框架开发的业务服务,与协议本身无关,治理的可以是 SOA服务,也可以是基于内部服务框架私有协议开发的各种服务。
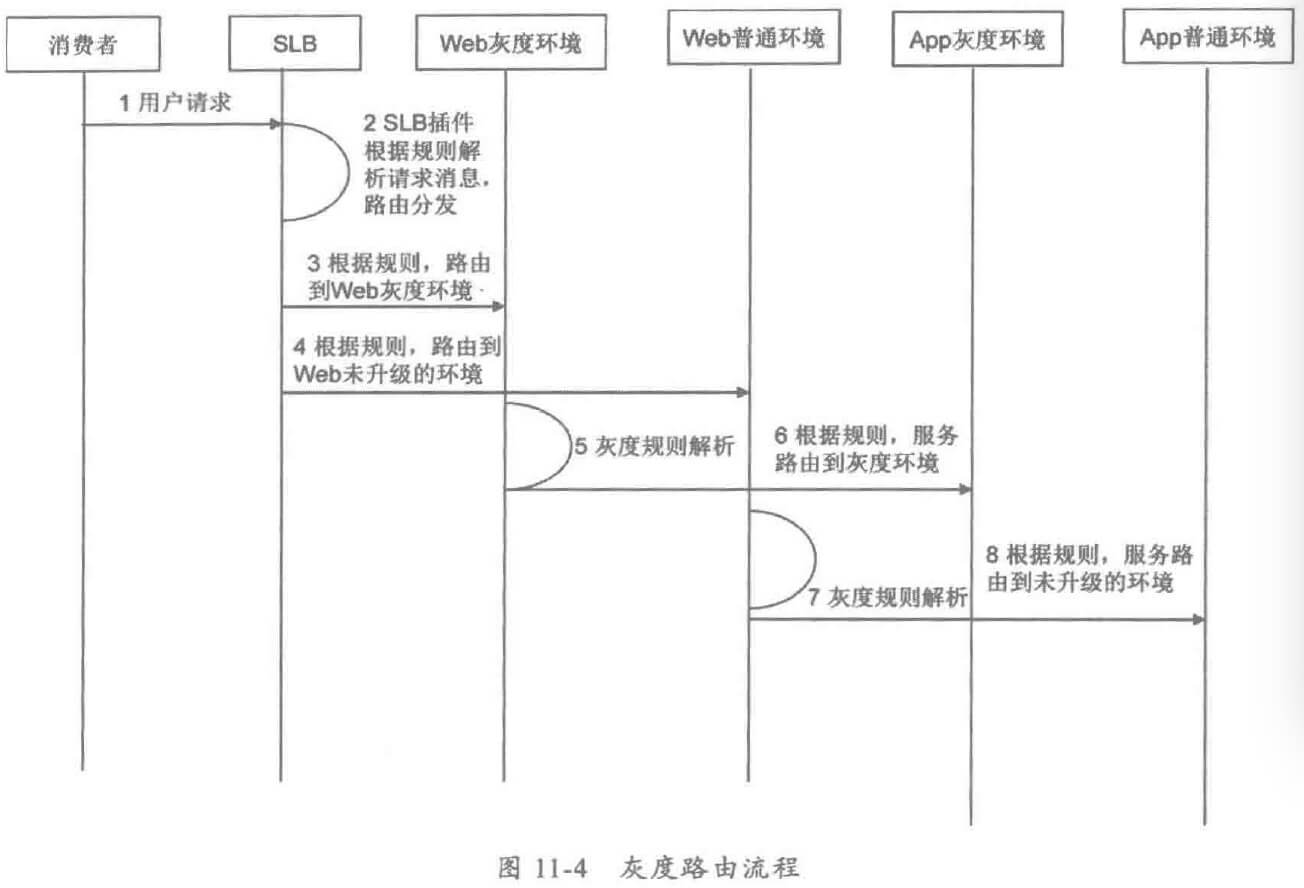
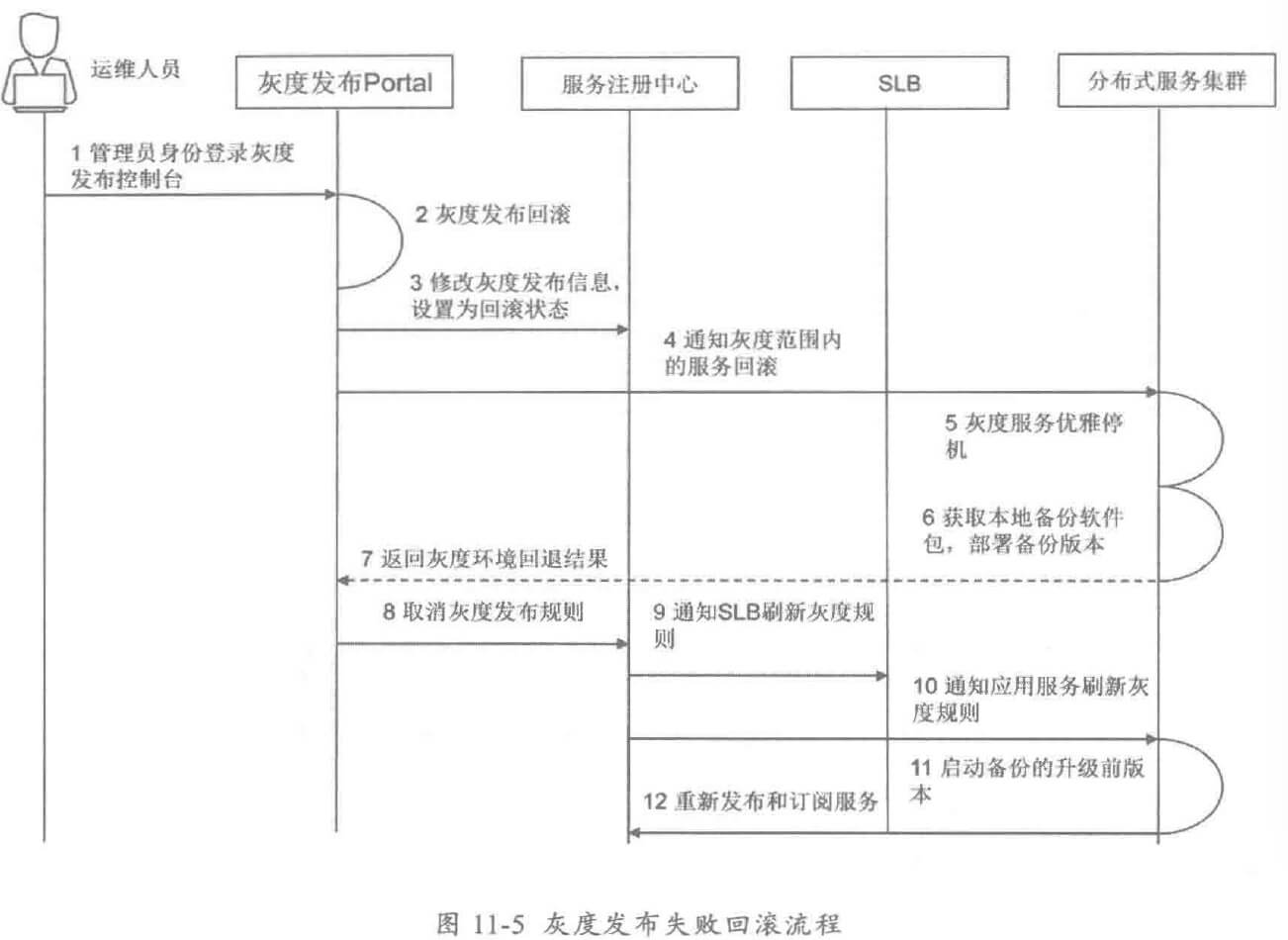
- 治理策略:针对互联网业务的特点,例如突发的流量高峰、网络延时、机房故障等,重点针对大规模跨机房的海量服务进行运行态治理,保障线上服务的高 SLA,满足用户的体验。常用的治理策略包括服务的限流降级、服务迁入迁出、服务动态路由和灰度发布等。
以分布式服务框架 Dubbo为例,它的服务治理体系如下: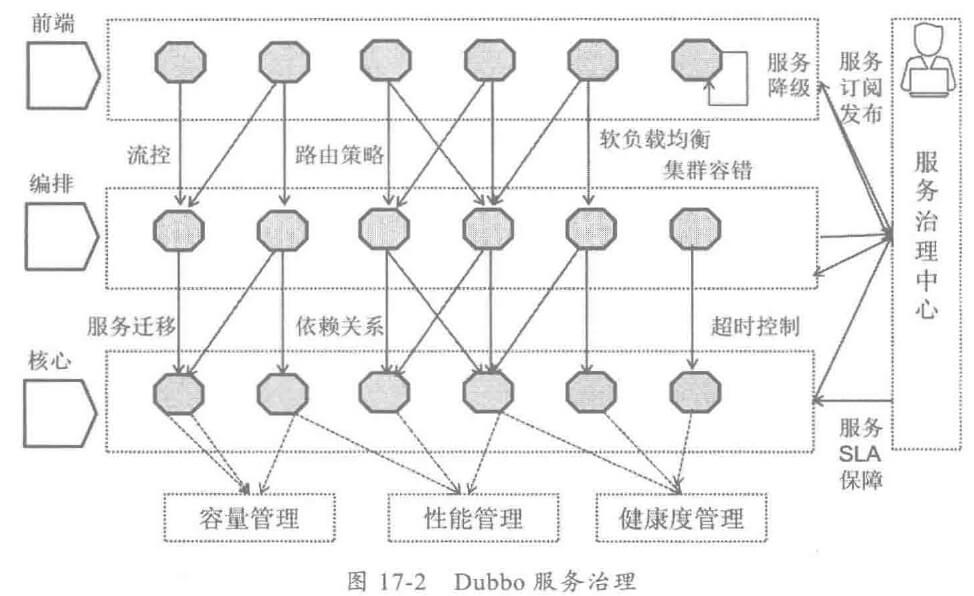
1.3 AWS 云端微服务治理
随着云计算的发展,Dev&Ops 逐渐流行起来,基础设施服务化(IaaS)为大规模、批量流水线式软件交付提供了便利,AWS 作为全球最大的云计算解决方案提供商,在微服务云化开发和治理方面积累了非常多的经验,具体总结如下:
- 全公司统一服务化开发环境,统一简单化服务框架(Coral Service),统一运行平台,快速高效服务开发。
- 所有后端应用服务化,系统由多项服务化组件构成。
- 服务共享、原子化、重用。
- 服务由小研发团队负责服务开发、测试、部署和治理,运维整个生命周期支撑。
- 高度自动化和 Dev&Ops 支持,一键式服务部署和回退。
- 超大规模支持:后台几十万个服务,成千上万开发者同时使用,平均每秒钟有 1~2 个服务部署。
- 尝试基于 Docket 容器部署微服务。
- 服务治理是核心:服务性能 KPI统计、告警、服务健康度管理、灵活的弹性伸缩策略、故障自动迁移、服务限流和服务降级等多种治理手段,保障服务高质量运行。
2 应用服务化后面临的挑战
2.1 跨团队协作问题
- 服务提供者 S分布式部署,存在多个服务实例,如果做端点调试,路由模块会动态分发消息,随机路由,服务提供者 S无法确定要连接的 IP地址。
- 如果打断点,其它消费者也正在进行服务调用,调试会被干扰,需要通知所有的开发者不要调用服务 S,显然不可能。
2.2 服务的上下线管控
需要结束某些服务的生命周期,服务提供者直接将服务下线,导致依赖该服务的应用不能正常工作。服务下线时,应先标记为过时,然后通知调用方尽快修改调用,通过性能 KPI接口和调用链分析,确认没有消费者再调用此服务,才能下线。
2.3 服务安全
针对内部应用,服务框架通常采用长链接管理客户端连接,针对非信任的第三方应用,或者恶意消费者,需要具备黑白名单访问控制机制,防止客户端非法链路过多,占用大量的句柄、线程和缓存资源,影响服务提供者的运行质量。
2.4 服务 SLA 保障
由于非核心服务跟系统其它服务打包部署在同一个 Tomcat等容器进程中,一旦非核心服务需要停止,也影响其它合设的服务,如何高效的关停非核心服务,但又不影响其它合设的服务,需要服务治理框架统一考虑。
另外超时时间也要方便的在线可视化的修改,不需要重启即可动态生效。
2.5 故障快速定界定位
由于分布式和大规模的部署,导致服务的 SLA将很难有效保障。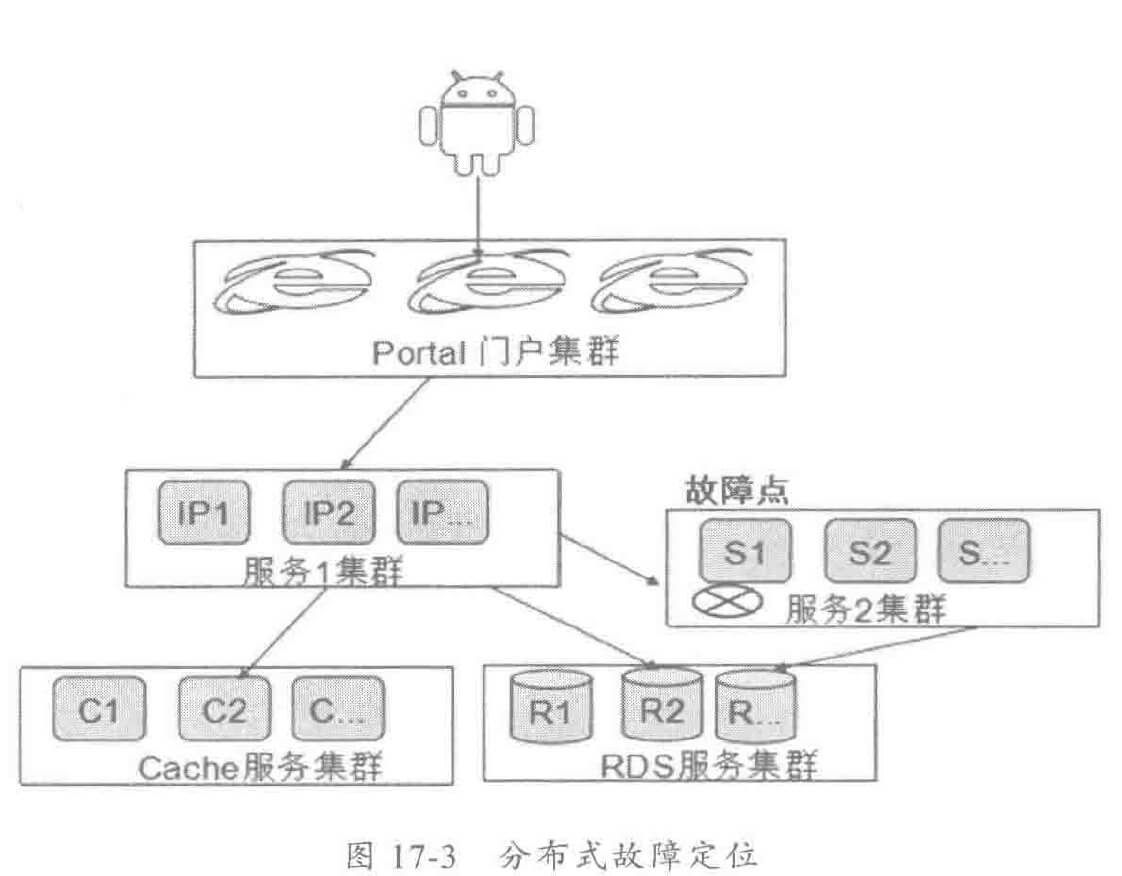
3 服务治理
分布式服务框架的服务治理目标如下:
- 防止业务服务架构腐化:通过服务注册中心对服务强弱依赖进行分析,结合运行时服务调用链关系分析,梳理不合理的依赖和调用路径,优化服务化架构,防止代码腐化。
- 快速故障定界定位:通过 Flume 等分布式日志采集框架,实时收集服务调用链日志、服务性能 KPI数据、服务接口日志、运行日志等,实时汇总和在线分析,集中存储和展示,实现故障的自动发现、自动分析和在线条件检索,方便运维人员、研发人员进行实时故障诊断。
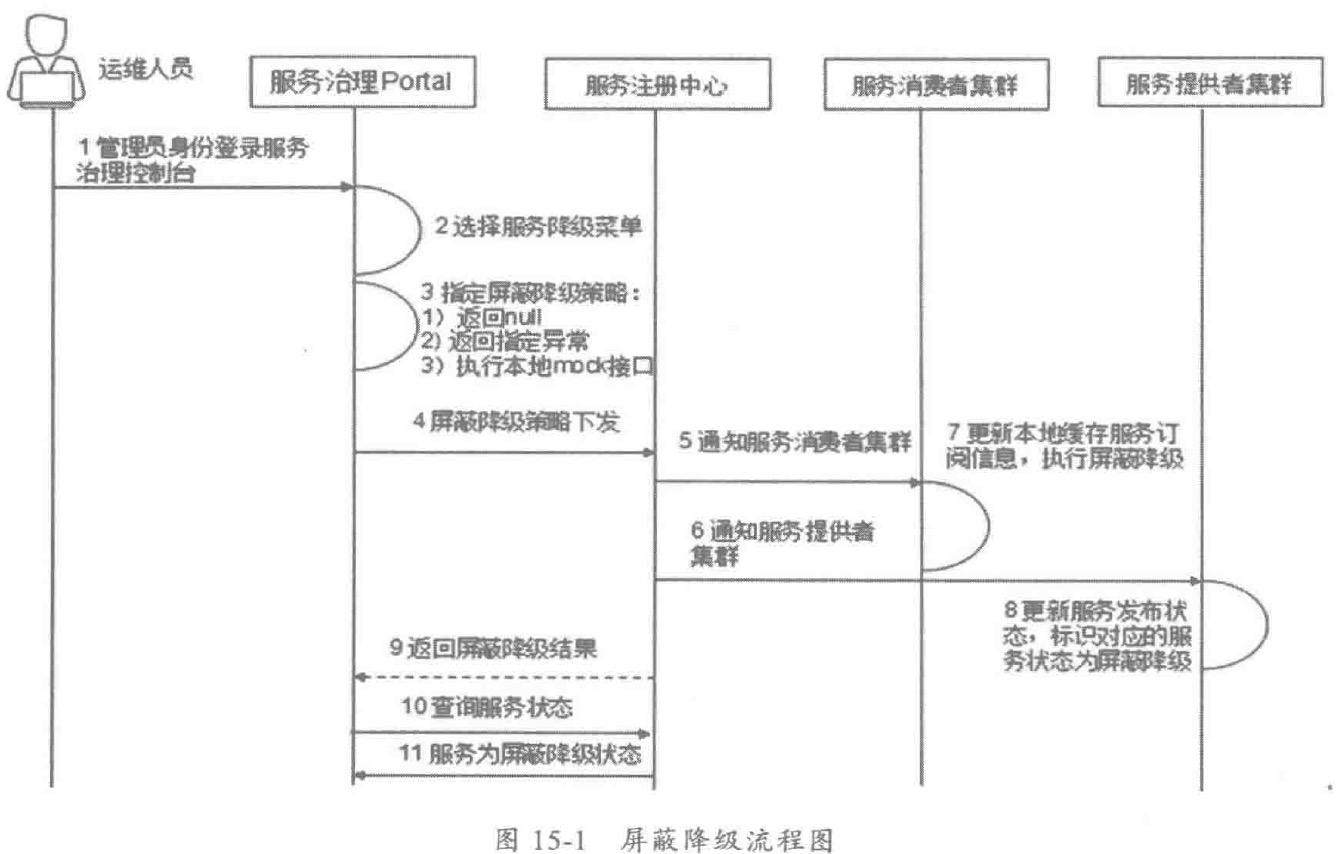
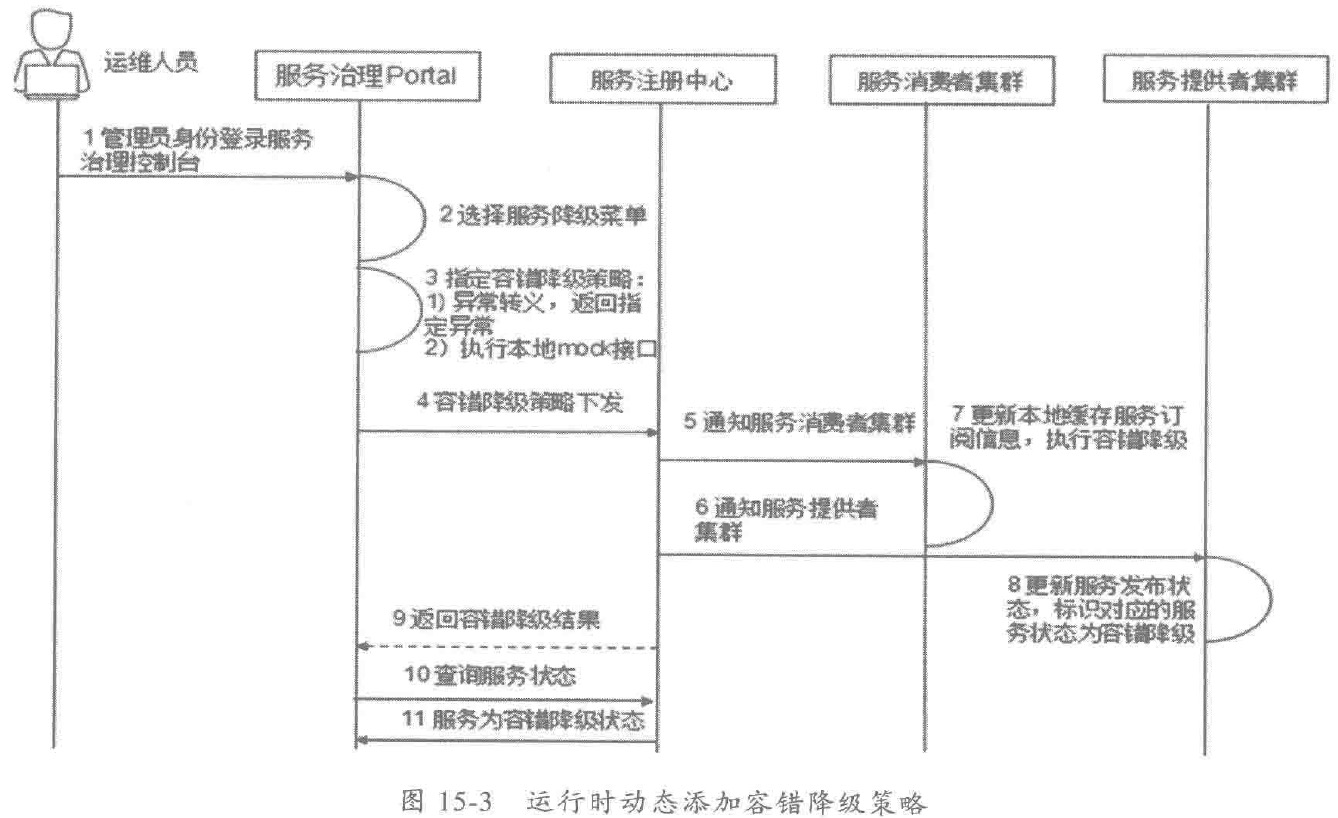
- 服务微管控:细粒度的运行期服务治理,包括限流降级、服务迁入迁出、服务超时控制、智能路由、统一配置、优先级调度和流量迁移等,提供方法级治理和动态生效功能,通过一系列细粒度的治理策略,在故障发生时可以多管齐下,在线调整,快速恢复业务。
- 服务生命周期管理:包括服务的上线审批、下线通知,服务的在线升级,以及线上和线下服务文档库的建设。
3.1 服务治理架构设计
分布式服务框架的服务治理分三层: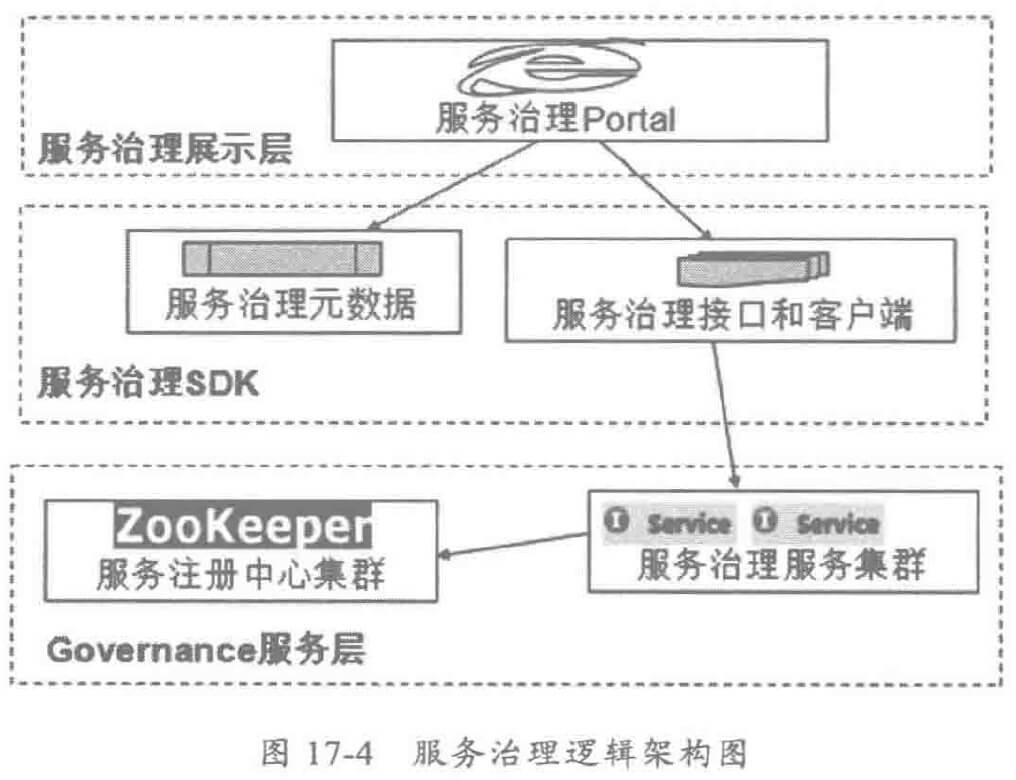
第二层为服务治理 SDK层,主要由如下组成:
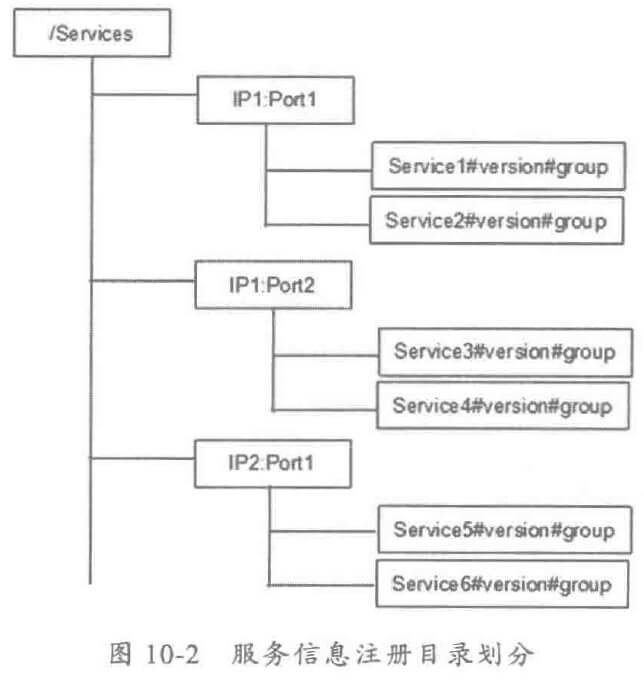
- 服务治理元数据:服务治理元数据主要包括服务治理实体对象,包括服务模型、应用模型、治理组织模型、用户权限模型、数据展示模型等。元数据模型通过 DataMapper和模型扩展,向上层界面屏蔽底层服务框架的数据模型,实现展示层和服务架构的解耦,元数据也可以用于展示界面的定制扩展。
- 服务治理接口:服务治理 Portal调用服务治理接口,实现服务治理。例如服务降级接口、服务流控接口、服务路由权重调整接口、服务迁移接口等。服务接口与具体的协议无关,它通常基于分布式服务框架自身实现,可以是 Restful接口,也可以是内部的私有协议。
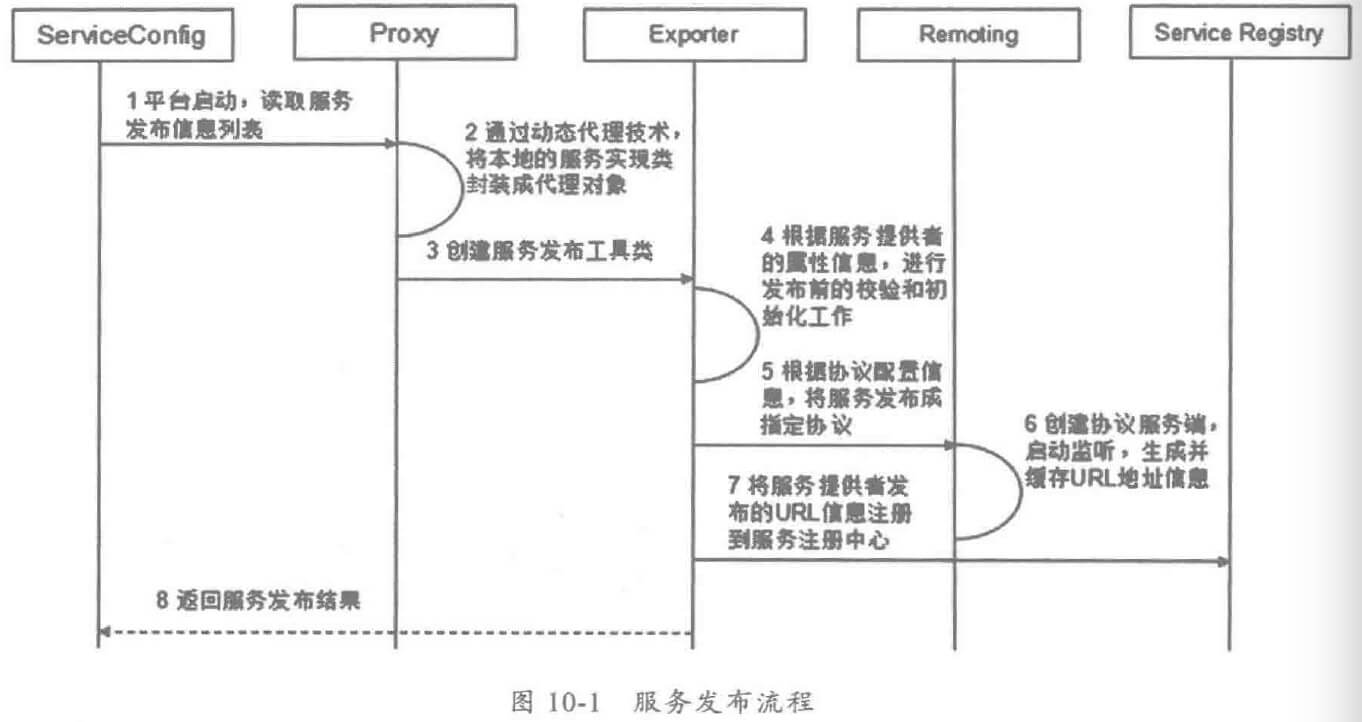
- 服务治理客户端类库:由于服务治理服务本身通常也是基于分布式服务框架开发,因此服务治理 Portal需要继承分布式服务框架的客户端类库,实现服务的自动发现和调用。
- 调用示例:客户端 SDK需要提供服务治理接口的参数说明、注意事项以及给出常见的调用示例,方便前端开发人员使用。
- 继承开发指南:服务治理 SDK需要提供继承开发指南。
3.2 运行态服务治理功能设计
运行态服务治理首先要做到可视:当前系统发布了哪些服务,这些服务部署在哪些机器上,性能 KPI数据如何,指标是否正常等。
由于性能 KPI数据的统计周期、统计指标和报表呈现方式差异比较大,因此服务框架很难抽象出一套放之四海而皆准的性能统计功能,因此在设计的时候需要注意以下两点:
- 扩展性:服务性能 KPI数据采集由插件 Handler 负责,平台和业务均可以通过扩展性能统计插件 Handler的方式扩展采集指标和采集周期等。
- 原子性:服务提供者和消费者只负责原始数据的采集和上报,不在本节点内做复杂的汇总操作,汇总和计算由性能汇聚节点的 Spark等大数据流式框架负责。
3.3 线下服务治理
为了解决消费者提供者之间的文档过时、错误问题,需要简历服务文档中心,方便线上运维人员查看和多团队之间的协作,它的工作原理如下:
基于 java DOC工具进行扩展,将规则内置到 IDE开发模板中,并通过 CI构建工具做编译检测,将不符合要求的服务接口输出到 CI构建报告并邮件发送给服务责任人。
服务的上线审批、下线通知机制需要建立并完善起来,工作原理如下:
3.4 安全和权限管理
安全涉及到两个层面:
- 服务的开放和鉴权机制。
- 服务治理的安全和权限管理。
服务治理的使用者通常分三类:
- 开发或者测试:主要定位问题,协助运维人员做服务治理。
- 运维人员:主要日常运维巡检,查看服务性能 KPI是否正常,是否有报警,利用服务治理进行故障恢复。
- 管理者:主要关心运营层面的 KPI数据,只看不管。
4 个人总结
服务治理总体结构图如下: