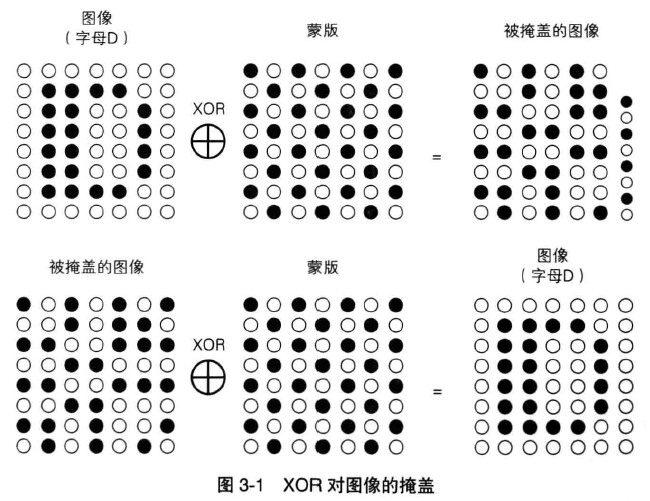
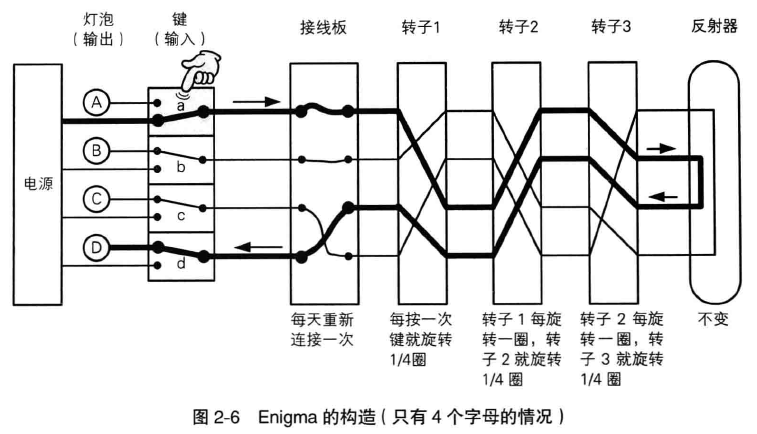
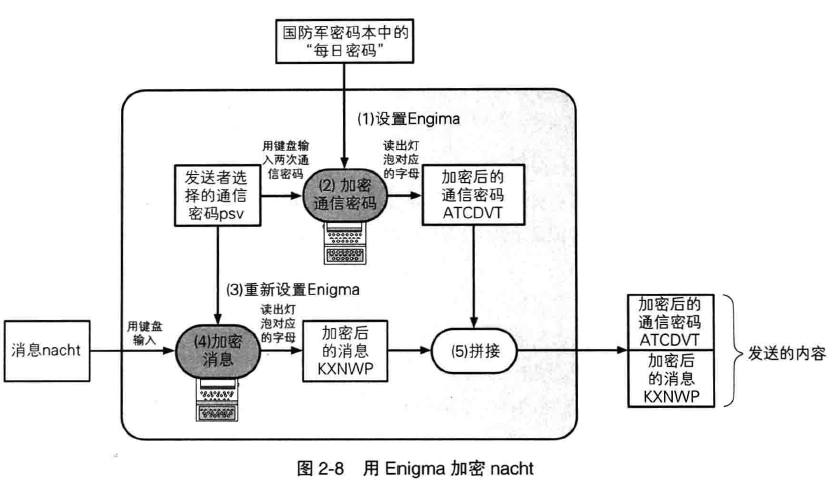
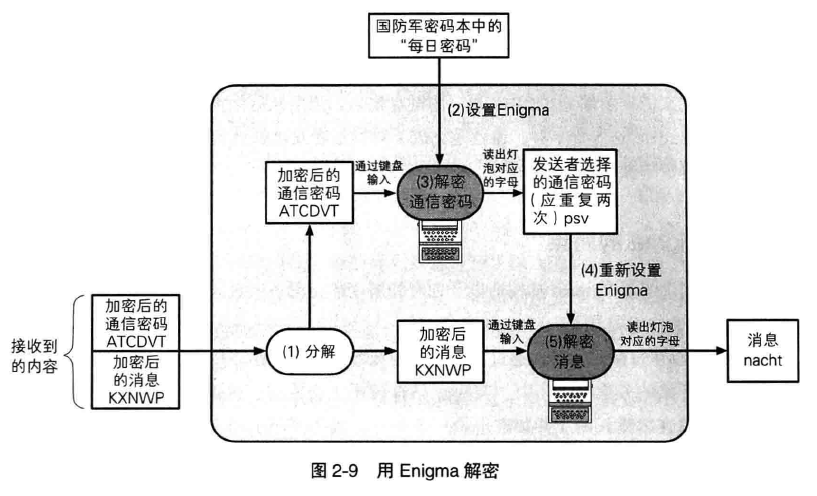
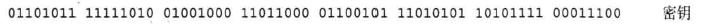1 投币寄物柜的使用方法
介绍公钥密码之前,先说说投币寄物柜:将物品放入寄物柜中,然后投入硬币并拔出钥匙,就可以将寄物柜关闭了。关闭后的寄物柜,没有钥匙是无法打开的。
只要有硬币,任何人都可以关闭寄物柜,但寄物柜一旦被关闭,只有使用钥匙才能打开,而不是硬币。
因此我们可以说,硬币是关闭寄物柜的密钥,而钥匙则是打开寄物柜的密钥。
2 本章概要
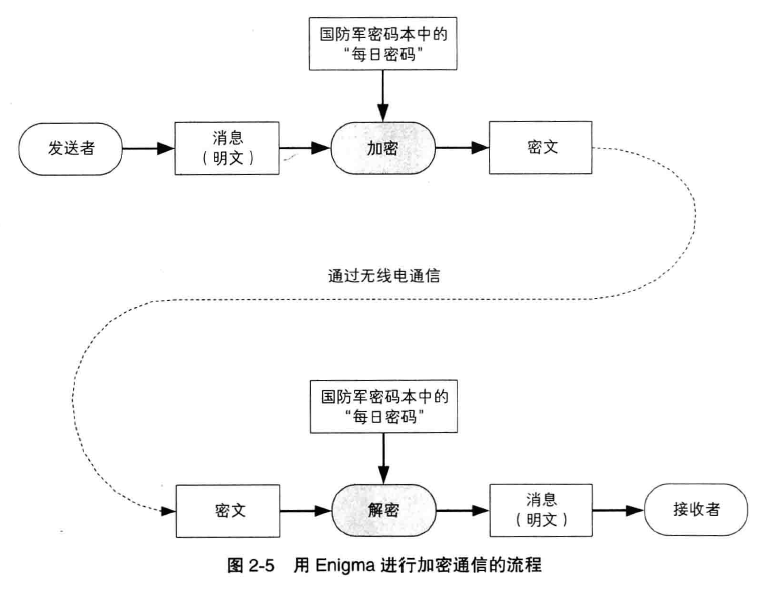
在对称密码中,由于加密和解密的密钥是相同的,因此必须向接收者配送密钥。用于解密的密钥必须被配送给接收者,这一问题称为密钥配送问题。如果使用
公钥密码,则无需向接收者配送用于解密的密钥,这样就解决了密钥配送问题。
本章先探讨一下密钥配送问题,然后再讲解公钥密码是如何解决密钥配送问题的。最后,将介绍一种最常用的公钥密码——RSA。
3 密钥配送问题
3.1 什么是密钥配送问题
在现实世界中使用对称密码时,我们一定会遇到密钥配送问题。由于密码算法本来就应该是以公开为前提的,隐蔽式安全性(security by obscurity)是
非常危险的。
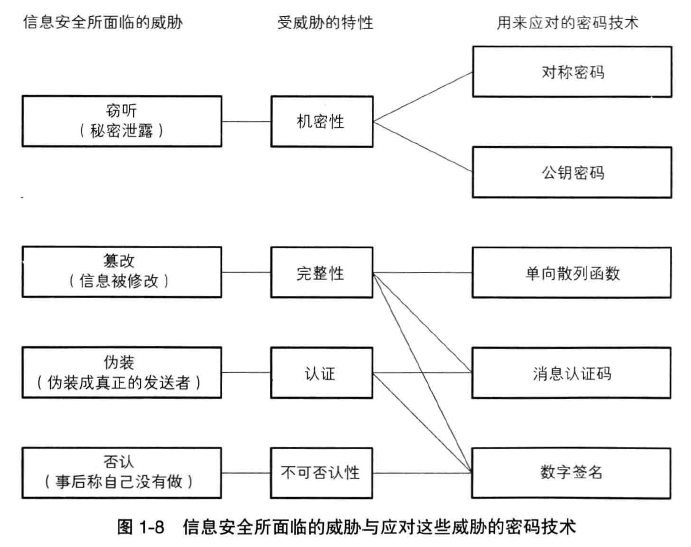
密钥必须要发送,但又不能发送,这就是对称密码的密钥配送问题,解决密钥配送问题的方法有以下几种:
- 通过事先共享密钥来解决
- 通过密钥分配中心来解决
- 通过 Diffie-Hellman 密钥交换来解决
- 通过公钥密码来解决
3.2 通过事先共享密钥来解决
事先用安全的方式将密钥交给对方,这称为密钥的事先共享。但是有一定的局限性,如果是网上认识的抑或需要邮寄的,都有可能被别人窃取。以及,如果一个
公司的 1000 名员工需要彼此进行加密通信,则需要 1000 * 999 / 2 = 499500 个密钥!
3.3 通过秘钥分配中心来解决
公司存在一台专门负责秘钥分配的计算机,它保存了所有员工的秘钥,当有新员工入职时,秘钥分配中心会为该员工生成一个新的秘钥,并保存。而新员工则会
从入职时从秘钥分配中心的计算机上领取自己的秘钥。
这样一来,秘钥分配中心就拥有所有员工的秘钥,而每个员工则拥有自己的秘钥。
那么 Alice 再向 Bob 发送加密邮件时,就需要进行以下步骤:
- Alice 向秘钥分配中心发出希望与 Bob 进行通信的请求
- 秘钥分配中心通过伪随机数生成器生成一个会话秘钥,这个秘钥是供 Alice 与 Bob 在本次通信中使用的临时秘钥
- 秘钥分配中心从数据库中取出 Alice 的秘钥和 Bob 的秘钥
- 秘钥分配中心用 Alice 的秘钥对会话秘钥进行加密,并发送给 Alice
- 秘钥分配中心用 Bob 的秘钥对会话秘钥进行加密,并发送给 Bob
- Alice 对来自秘钥分配中心的会话秘钥(已使用 Alice 的秘钥加密)进行解密,得到会话秘钥
- Alice 用会话秘钥对邮件进行加密,并将邮件发送给 Bob
- Bob 对来自秘钥分配中心的会话秘钥(已使用 Bob 的秘钥加密)进行解密,得到会话秘钥
- Bob 用会话秘钥对来自 Alice 的密文进行解密
- Alice 和 Bob 删除会话秘钥
以上就是通过秘钥分配中心完成 Alice 与 Bob 的通信过程,缺点显而易见:
- 随着员工增加,秘钥分配中心负荷增大
- 如果秘钥分配中心计算机发生故障,全公司的加密通信就会瘫痪
- 攻击者直接对秘钥分配中心下手,盗取秘钥数据库,后果十分严重
3.4 通过 Diffie-Hellman 秘钥交换来解决秘钥配送问题
解决秘钥配送问题的第三种方法,称为 Diffie-Hellman 秘钥交换。这里的交换,指的是发送者和接收者之间相互传递信息的意思。
根据交换的信息, Alice 和 Bob 可以生成相同的秘钥,而窃听者就算得到交换的信息,也无法生成相同的秘钥,将在第十一章详解。
3.5 通过公钥密码来解决秘钥配送问题
第四种方法,就是公钥密码。
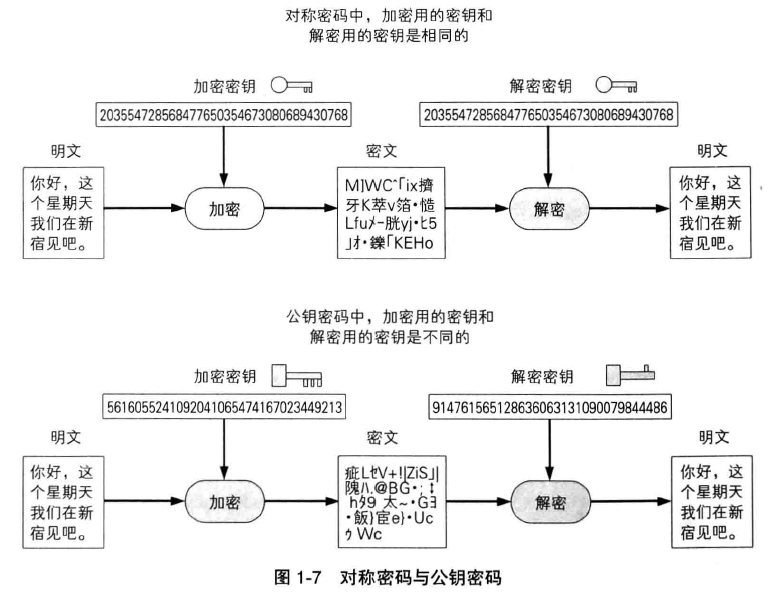
在公钥密码中,加密秘钥和解密秘钥不同,只要拥有加密秘钥,任何人都可以进行加密,但没有解密秘钥是无法解密的。因此,公钥密码的重要特性是,只有拥有
解密秘钥的人才能够进行解密。
接受者事先将加密秘钥发送给发送者,这个加密秘钥即使被窃听获取也没问题。发送者使用加密秘钥对通信内容进行加密并发送给接收者,而只要拥有解密秘钥
的人(即发送者本人)才能够解密。这样,就不用讲解密秘钥配送给接收者了,也就是说,对称密码的秘钥配送问题,可以通过使用公钥密码来结局。
4 公钥密码
4.1 什么是公钥密码
公钥密码(public-key cryptography)中,秘钥分为加密秘钥和解密秘钥两种。加密秘钥是发送者加密时使用的,而解密秘钥则是接收者解密时使用的。
加密秘钥和解密秘钥的区别:
- 发送者只需要加密秘钥
- 接收者只需要解密秘钥
- 解密秘钥不可以被窃听者获取
- 加密秘钥被窃听者获取也没问题
也就是说,解密秘钥从一开始就是由接收者自己保管的,因此只要将加密秘钥发送给发送者就可以解决秘钥配送问题了,根本不需要配送解密秘钥。
公钥和私钥是一一对应的,一对公钥和私钥统称为密钥对(key pair)。由公钥进行加密的密文,必须使用与该公钥配对的私钥才能够解密。
4.2 公钥密码的历史
- 1976年发表了关于公钥密码的设计思想,即将加密秘钥和解密秘钥分开。
- 1977年设计了一种具体的公钥密码算法,但后来被发现并不安全。
- 1978年发表了一种公钥密码算法——RSA,可以说是现在公钥密码的事实标准。
4.3 公钥通信的流程
Alice 是发送者, Bob 是接收者, Eve 是窃听者。在公钥密码通信中,通信过程是由接收者 Bob 来启动的:
- Bob 生成一个包含公钥和私钥的密钥对。私钥由 Bob 自行妥善保管。
- Bob 将自己的公钥发送给 Alice 。公钥被 Eve 获得。
- Alice 用 Bob 的公钥对消息进行加密。
- Alice 将密文发送给 Bob 。密文被 Eve 获得。
- Bob 用自己的私钥对密文进行解密。
4.4 公钥密码无法解决的问题
我们需要判断所得到的公钥是否正确合法,这个问题被称为公钥认证问题。这个问题随后将通过对中间人攻击的讲解来探讨。
同时,公钥密码的处理速度只有对称密码的几百分之一,随后在下节详解。
5 时钟算法
在讲解公钥密码的代表 RSA 之前,我们需要做一些数学方面的准备工作。
5.1 加法
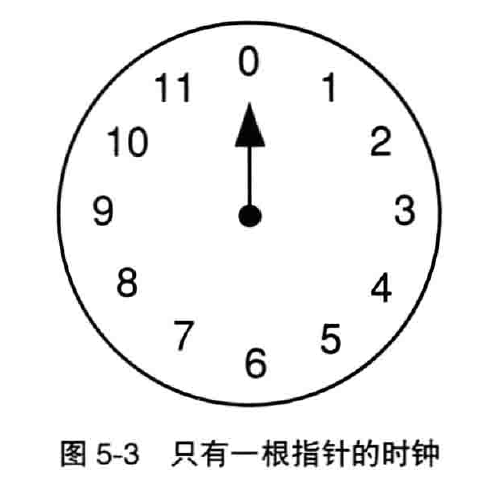
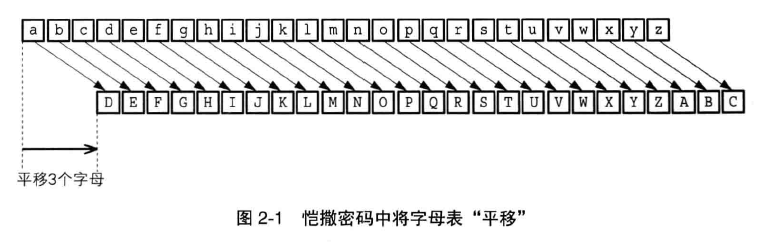
指针从 11 在转就回变成 0 。即,如果当前是 5 点, 11 个小时后为:x = 5 + 11%12 = 5 - 1 = 4 。
因此加法就变成了求余数运算,即 mod 运算。
5.2 减法
减法是加法的逆运算:如果当前是 5 点, 11 个小时之前是:x + 11%12 = 5 => x = 6。
5.3 乘法
乘法即多个加法:如果当前是 5 点, 乘以 3: 5 + 5%12 + 5%12 = -9 => -9 + 12 = 3。
5.4 除法
除法是乘法的逆运算:但是,由于时钟只能是整数,因此并不是所有的数都能当被除数,要保证被除后是一个整数。
5.5 乘方
7^4:7^4 mod 12 = 2401 mod 12 = 1
5.6 对数
即乘方的逆运算:7^X = Y ,已知 Y 求 X。
在时钟运算中的对数称为离散对数。例如:
7^X mod 12 = 8,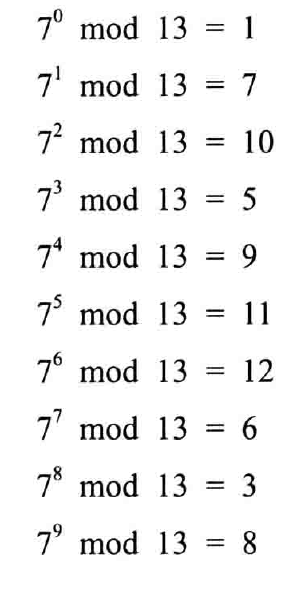
得到结果为 9 。当数字很大时,求离散对数非常困难,也非常耗时。能快速求出离散对数的算法到现在还没有被发现。
5.7 从时钟指针到 RSA
我们知道了 7^4 mod 12 代表的含义,那么就为理解 RSA 做好准备了,因为 RSA 的加密和解密过程中所进行的正是这样的运算。
6 RSA
6.1 什么是 RSA
RSA 是一种公钥密码算法,它的名字是由它的三位开发者,即 Ron Rivest、 Adi Shamir 和 Leonard Adleman 的姓氏首字母组成的。
RSA 可以被用于公钥密码和数字签名,数字签名将在第九章详解。
RSA 在 1983年取得了专利,但现在专利已经过期。
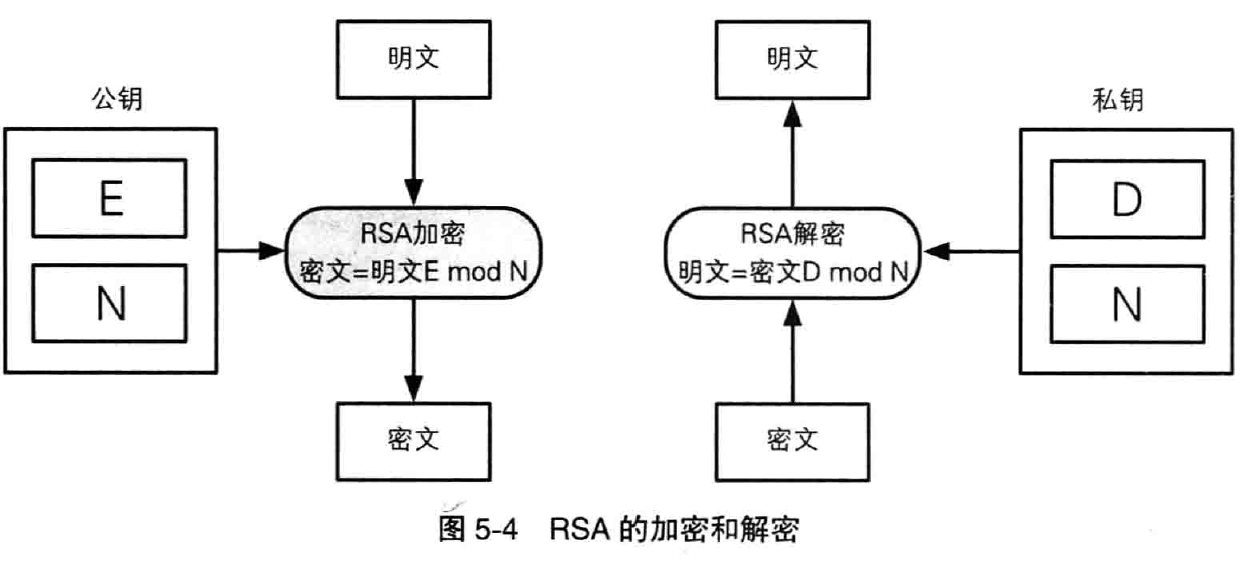
6.2 RSA 加密
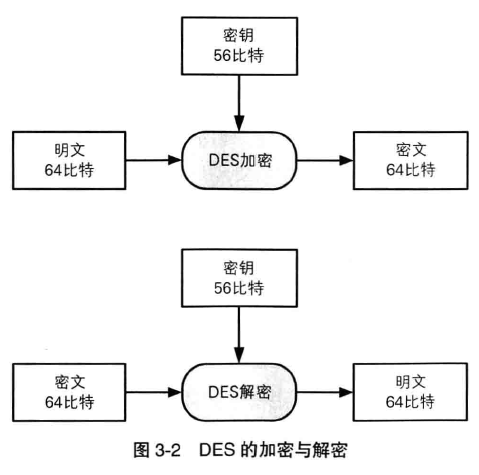
在 RSA 中,明文、秘钥和密文都是数字, RSA 的加密过程可以用下列公式来表示:
密文 = 明文 ^ E mod N
也就是说, RSA 的密文是对代表明文的数字的 E 次方求 mod N 结果。换句话说,就是将明文和自己做 E 次乘法,然后将其结果除以 N 求余数,这个余数就是密文。
就是这么简单。
其中 E 和 N 时 RSA 加密的秘钥,也就是说, E 和 N 的组合就是公钥。注意:E 和 N 并不是密钥对,“公钥是(E,N)”这种写法。
现在大家应该已经知道, RSA 的加密就是“求 E 次方的 mod N”。
6.3 RSA 解密
明文 = 密文 ^ D mod N
也就是说,对表示密文的数字的 D 次方求 mod N 就可以得到明文。
RSA 的加密和解密整理如下:
6.4 生成密钥对
由于 E 和 N 是公钥,D 和 N 是私钥,因此求 E、D 和 N 这三个数就是生成秘钥对。步骤如下:
- 求 N
- 求 L(中间值)
- 求 E
- 求 D
注:由于博主并不深究生成过程,只需要知道使用到了最大公约数以及质数的特性即可,有需要深究具体生成的请自行 Google。
7 对 RSA 的攻击
RSA 的加密是求 “E 次方的 mod N”,解密时求 “D 次方的 mod N”,原理非常简单。
破译者知道的信息:密文、E、N。
破译者不知道的信息:明文、D、一些密码算法所使用的中间变量。
7.1 通过密文来求得明文
密文 = 明文 ^ E mod N
如果没有 mod N运算,只有 密文 = 明文 ^ E ,就很简单,即求对数的问题。但是如果加上 mod N运算,就变成求离散对数的问题,这是非常困难,
因为人类还没有发现求离散对数的高效算法。
7.2 通过暴力破解来找出 D
由于暴力破解的难度会随 D 的长度增加而变大,因此 D 到达 1024 比特以上,暴力破解就很难在现实的时间内通过暴力破解找出数 D。
7.3 通过 E 和 N 求出 D
既然 D 本身是通过 E 和 N 求出,因此破译者也可以尝试,但是由于涉及到质数分解的问题,这样的方法目前还没有出现,而且我们也不知道是否真的存在这个方法。
7.4 中间人攻击
下面介绍一种名为中间人攻击(man-in-the-middle attack)的攻击方法。这种方法虽然不能破译 RSA,但却是一种针对机密性的有效攻击。
假设发送者 Alice 准备向接收者 Bob 发送一封邮件,为了解决密钥配送问题,他们使用了公钥密码。
- Alice 向 Bob 发送邮件索要公钥
- Mallory 通过窃听发现 Alice 在向 Bob 索要公钥。
- Bob 看到 Alice 的邮件,并将自己的公钥发送给 Alice。
- Mallory 拦截 Bob 的邮件,使其无法发送给 Alice 。然后,他悄悄地将 Bob 的公钥保存起来。
- Mallory 拦伪装成 Bob,将自己的公钥发送给 Alice。
- Alice 将自己的消息用 Bob 的公钥(其实是 Mallory 的公钥)进行加密并发送给 Bob。
- Mallory 拦截 Alice 的加密邮件。用 Mallory 的私钥解密,得到明文。
- Mallory 伪装成 Alice 给 Bob 写一封假邮件并用保存起来的 Bob 的公钥加密发送给 Bob。
Mallory 不仅可以篡改 Alice 消息,还可以篡改 Bob 的消息。中间人攻击进不仅针对 RSA,而是针对在座的各位公钥密码!
我们用公钥密码解决了密钥配送问题,但是又出现新的问题,如何判断收到的公钥是否来自于正确的接收者,即是否来自于 Bob 。解决这个问题成为认证,
将在第十章详解。
8 其它公钥密码
RSA 是现在最为普及的一种公钥密码算法,但除了 RSA 之外,还有其它的公钥密码。下面介绍一下 EIGamal 方式、Rabin 方式以及椭圆曲线密码。
这些密码都可以被用于一般的加密和数字签名。
8.1 EIGamal 方式
RSA 利用了质因数分解的困难度,而 EIGamal 方式利用了 mod N 下求离散对数的困难度。它的缺点是,密文是明文的两倍。
8.2 Rabin 方式
Rabin 利用了 mod N 求平方根的困难度。
8.3 椭圆曲线密码
椭圆曲线密码(Elliptic Curve Cryptosystems,ECC)是最近备受关注的一种公钥密码算法。它的特点是所需的密钥长度比 RSA 短。
它通过将椭圆曲线上特定点进行特殊的乘法运算来实现的,利用了这种乘法运算的逆运算非常困难这一特性。
9 关于公钥密码的问答
主要选择一些容易被误解的点解答疑问。
9.1 公钥密码的机密性
公钥密码比对称密码的机密性更高吗?
这个问题无法回答,因为机密性的高低是根据密钥长度而变化的。
9.2 公钥密码与对称密码的密钥长度
采用 1024 比特的密钥的公钥密码,和采用 128 比特的密钥的对称密码中,是密钥更长的公钥密码更安全吗?
不是。公钥密码的密钥长度不能与对称密码的密钥长度进行直接比较,如下是一张密钥长度的比较表(摘自《应用密码学》),看出, 1024 比特的公钥密码与
128 比特的对称密码相反,反而是 128 比特的对称密码抵御暴力破解的能力更强。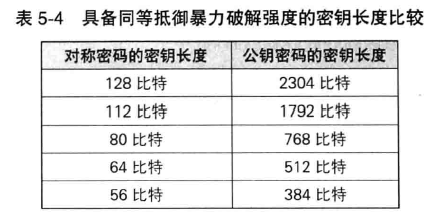
9.3 对称密码的未来
因为已经有了公钥密码,今后对称密码会消失吗?
不会。一般来说,在采用具备同等机密性的密钥长度的情况下,公钥密码的处理速度只有对称密码的几百分之一。因此,公钥密码不适合用来对很长的消息内容进行加密。
根据目的的不同,可能会配合使用对称密码和公钥密码,将在第六章介绍的混合密码系统详解。
9.4 RSA 和质数
随着越来越多的人在不断地生成 RSA 的密钥对,质数会不会被用光?
512 比特能够容纳的质数的数量大概是10^150。假设世界上有 100 亿人,每人每秒生成 100 亿个密钥对,经过 100 亿年后:
100亿人100亿个31622400秒*100亿年 < 10^39。
另外,理论上质数组合偶然撞车的可能性,事实上也可以认为是没有的。
9.5 RSA 与质因数分解
RSA 的破译与大整数的质因数分解是等价的吗?
不清楚是否是等价的。但是,只要能够快速完成质因数分解,就能够破译 RSA。
9.6 RSA 的长度
要抵御质因数分解,N 的长度需要达到多少比特呢?
N 无论多长,总有一天能够被质因数分解。在 1999年 521比特的证书由 292台计算机话费 5.2 个月完成了质因数分解。
10 本章小结
本章学习了公钥密码以及其代表性的实现方法——RSA。
使用公钥密码能够解决秘钥配送问题。公钥密码是密码学界的一项革命性的发明!
对称密码通过将明文转换为复杂的形式来保证其机密性,相对的,公钥密码则是局域数学上困难的问题来保证机密性的。例如 RSA 就利用了大整数的质因数分解
问题的难度。因此,对称密码和公钥密码源于两个根本不同的思路。
尽管公钥密码解决了秘钥配送问题,但针对公钥密码能够进行中间人攻击。要防御这种攻击,就需要回答“这个公钥是否属于合法的通信对象”这一问题,这个问题
将在第九章和第十章详解。
即使已经有了公钥密码,对称密码也不会消失。公钥密码的运行速度远远低于对称密码,因此在一般的通信过程中,往往会配合使用这两种密码,即用对称密码
提高处理速度,用公钥密码解决秘钥配送问题,这种方式称为混合密码系统,将在下一章详解。
11 小测验
- 秘钥分配中心的处理:当 Alice 发出希望与 Bob 进行通信的请求时,秘钥分配中心会生成一个全新的会话秘钥,并将其加密后发送给 Alice 。
为什么秘钥分配中心不直接将 Bob 的秘钥用 Alice 的秘钥加密之后发送给 Alice 呢? - 要对用公钥密码加密的密文进行解密,需要公钥密码的私钥。
- 公钥密码的私钥需要和加密后的消息一起被发送给接收者。
- 一般来说,对称密码的速度比公钥密码要快。