2020/01周总结
除非你觉得你的时间不是很宝贵,否则不要看这篇流水账式的博文,这只是篇个人的工作的学习一个总结而已,没有包含任何的技术细节
线程池一直对其中的线程销毁机制有点模糊,在网上找了很多文章,终于找到:https://juejin.im/post/5c33400c6fb9a049fe35503b。
该文通过源码入手分析,写的真不错!
而本文两个目的:一是能让自己能给别人讲懂任务如何的执行以及讲懂线程如何的销毁。
每个任务会包装成 Worker 执行,在执行时,先执行 addWorker() 方法,添加入 workers,接着执行 Worker.run。
每个 worker 执行都通过死循环调用 getTask() 方法堵塞,这个方法又是通过死循环不断的从队列中取任务执行。
线程销毁通过 getTask() 方法以及 processWorkerExit() 这两个方法实现,前者通过 queue 的 poll 做定时堵塞,后者通过 workers.remove 来做线程的移除。
一步一步的复习锁,从 Synchronized 到 AQS,其实还有 volatile,但是它是可见性和原子性的保证,和锁还是有本质区别的,就没有纳入了。
对象头:每个对象都有一个对象头,里面存储了锁类型(是否偏向锁、轻量锁、重量锁)、GC 标记、对象分代年龄等。
monitor:ObjectMonitor 对象,也叫监视器,每个对象都有一个对应的监视器,里面包括处于阻塞该对象锁的线程以及处于等待该对象锁的线程(前者是排队获取锁、后者是 wait 方法)。
每个对象都有对应的一个 monitor,哪个线程获取到 monitor,就得到了该对象的锁。线程实际通过操作对象头来控制对象的锁。是否为重量锁、轻量锁,是通过对象头的标识来确定锁类型,他们可以转换,即从轻量锁转换成重量级锁等。
Synchronized 对应两条指令:monitorenter、monitorexit。这两条指令表明某个线程持有某个 monitor,以及释放某个 monitor。
其中 wait/notify 表示:将对象当前被持有的锁放入等待队列,因此这个操作是需要提前获取锁,即需要在 Synchronized 代码块内操作。notify 表示唤醒对象被持有的锁。
CAS:compare and swap,基于 UnSafe 类来实现,UnSafe 通过指针操作与操作系统交互,最终依赖操作系统的 CAS 指令完成。
虽然是无锁技术,但是并不代表性能比有锁技术高,因为当锁竞争严重时,会不断的在循环中 CAS 操作,性能会很低。
long、double 占用8字节,也就是64比特,而在 32 位操作系统对 64 位的数据读写要分两步。这个没有做试验。
从 1.7 的 Segment + HashEntry 到 1.8 的 Synchronized + CAS + 红黑树,比之前的分段锁更加细粒,头结点使用的 CAS 插入,冲突失败后使用 Synchronized 获取头结点锁进行后续操作。
AQS 核心在于使用的 CAS 来改动 status 状态值,作为是否持有锁,可重入锁等。以及额外包括了等待队列 CLH,该等待队列用于阻塞线程后的排队容器,因此可以设置排队是否公平。而 ReentrantLock 本质就是 AQS 的一个实现。
好久没动脑子去思考 hashmap 的设计了,这次做个简单分析。
1 | static final int hash(Object key) { |
原hash:1111 1111 1111 1111 1111 1010 0111 1100
右移16位:0000 0000 0000 0000 1111 1111 1111 1111
异或运算:1111 1111 1111 1111 0000 0101 1000 0011
在低16位中,让高低16位都参与进行了异或,尽量避免一些hash值后续出现冲突,大家可能会进入数组的同一个位置,增加链表长度。
(n - 1) & hash,即 hash 对 n 取模结果一样。
高位没有参与与运算。
数组长度为 16 时:
n-1:0000 0000 0000 0000 0000 0000 0000 1111
hash:1111 1111 1111 1111 0000 1111 0000 0101
&结果:0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)
n-1:0000 0000 0000 0000 0000 0000 0000 1111
hash:1111 1111 1111 1111 0000 1111 0001 0101
&结果:0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)
数组长度为 32 时:
n-1:0000 0000 0000 0000 0000 0000 0001 1111
hash:1111 1111 1111 1111 0000 1111 0000 0101
&结果:0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)
n-1:0000 0000 0000 0000 0000 0000 0001 1111
hash:1111 1111 1111 1111 0000 1111 0001 0101
&结果:0000 0000 0000 0000 0000 0000 0001 0101 = 21(index = 5+16的位置)
因此,只需要判断结果是否多了一个 bit 的 1,来决定新的 index 是不变,还是等于 index + oldCap
该文为回答该 Issue 的答案:https://github.com/Snailclimb/JavaGuide/issues/567
之前研究过一段时间,用的是 Redisson 框架,这里是 Redission 实现 Redlock 的官方文档 。以下为个人见解,可能有误
重点如下:
集群模式:Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redlock:有 N 个 Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。
这里 Redlock 的使用有四个要求,一是需要 N 个 Redis master,二是节点独立、三是不存在主从复制、四是不存在集群协调机制。后三个要求其实就说明了,你要用的这些 master 不能同时存在同一个集群中。
以下用图加深理解

红框代表的是一个标准的 Redis 集群:它是有六个 Redis 节点间共享数据的程序集。
对于 Redlock 来说,这个集群中的两个 Master 不是互相独立的,而且是有集群协调机制的。因此它们不符合使用 Redlock 的场景。你会想,那我只连接一个 Master 可以吧,是可以的,但是也不是标准的 Redlock 的,因为不符合 N 个 Redis master 要求。
综上:如果你只有一个标准的集群,无论里面有多少个 Master,都是不符合 Redlock 的使用场景的,主要在于一个集群内的 Master 间它们不是互相独立的。
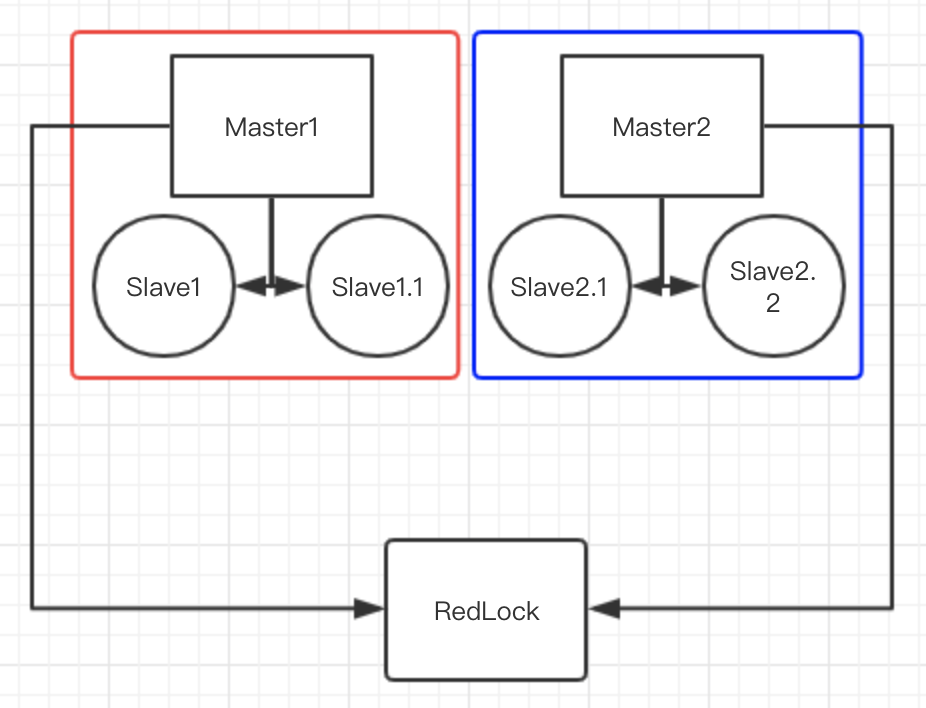
红框和蓝框分别代表两个独立的标准的 Redis 集群,它们分别是有三个 Redis 节点间共享数据的程序集。
对于 Redlock 来说,一共有两个符合要求的 Master,因此是符合 Redlock 的使用场景。这两个 Master 的同步只在自己的集群内和 Slave 同步。但是不允许这两个 Master 跨集群间同步,因为如果跨集群同步了,那么就不符合 Master 互相独立的要求了。
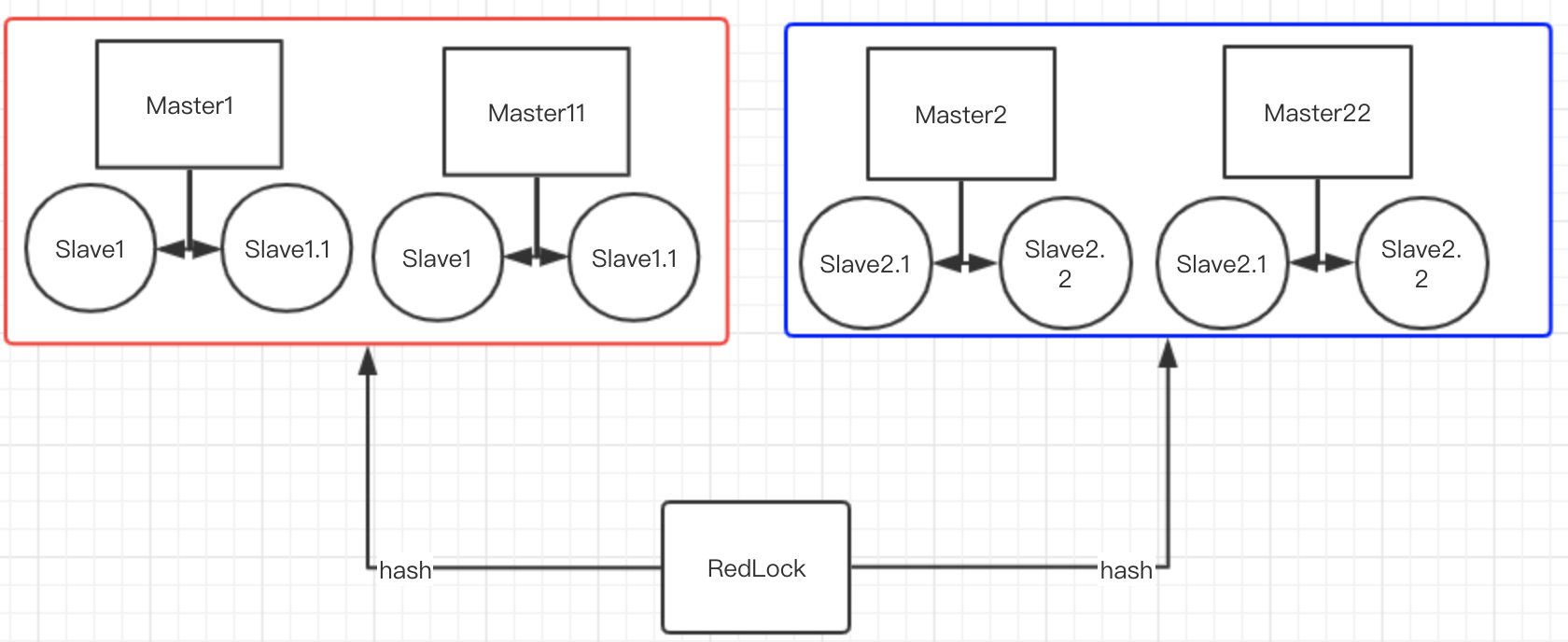
这里每个集群内部有两个 Master,此时对于 Redlock 来说,它只认为有一组 Master(Master1-Master2、Master1-Master22、Master11-Master2、Master11-Master22) 是互相独立的。(前提在于这两个集群之间并不同步)
其实这里说的并不严谨。这里涉及 Redis 集群的哈希槽知识,对于客户端来说,连接 Redis 集群时,连接该集群下的任意一个节点即可,集群会自动给你对 key 做 hash,然后映射到不同的 Master 上,因此对于客户端来说,其实一个集群无论里面有多少个 Master 节点,客户端只会以为有一个节点。
关于图的连线,是直接连接 Master 还是连接集群,其实这里要说一下 Redis-cluster,客户端连接集群时,选择集群的任意一个节点连接,在集群中会自动转发到对应的 Master 做操作。
如果有错误请指正。