随着业务分布式架构的发展,系统间的系统调用日趋复杂,以电商的商品购买为例,前台界面的购买操作设计到底层上百次服务调用,涉及到的中间件包括:
- 分布式服务框架
- 消息队列
- 分布式缓存
- 分布式数据访问中间件
- 分布式文件存储系统
- 分布式日志采集
- 其它……
如果无法有效清理后端的分布式调用和依赖关系,故障定界将会非常困难。利用分布式消息跟踪系统可以有效解决服务化之后系统面临的运维挑战,提高运维效率。
1 业务场景分析
以下为分布式调用示意图: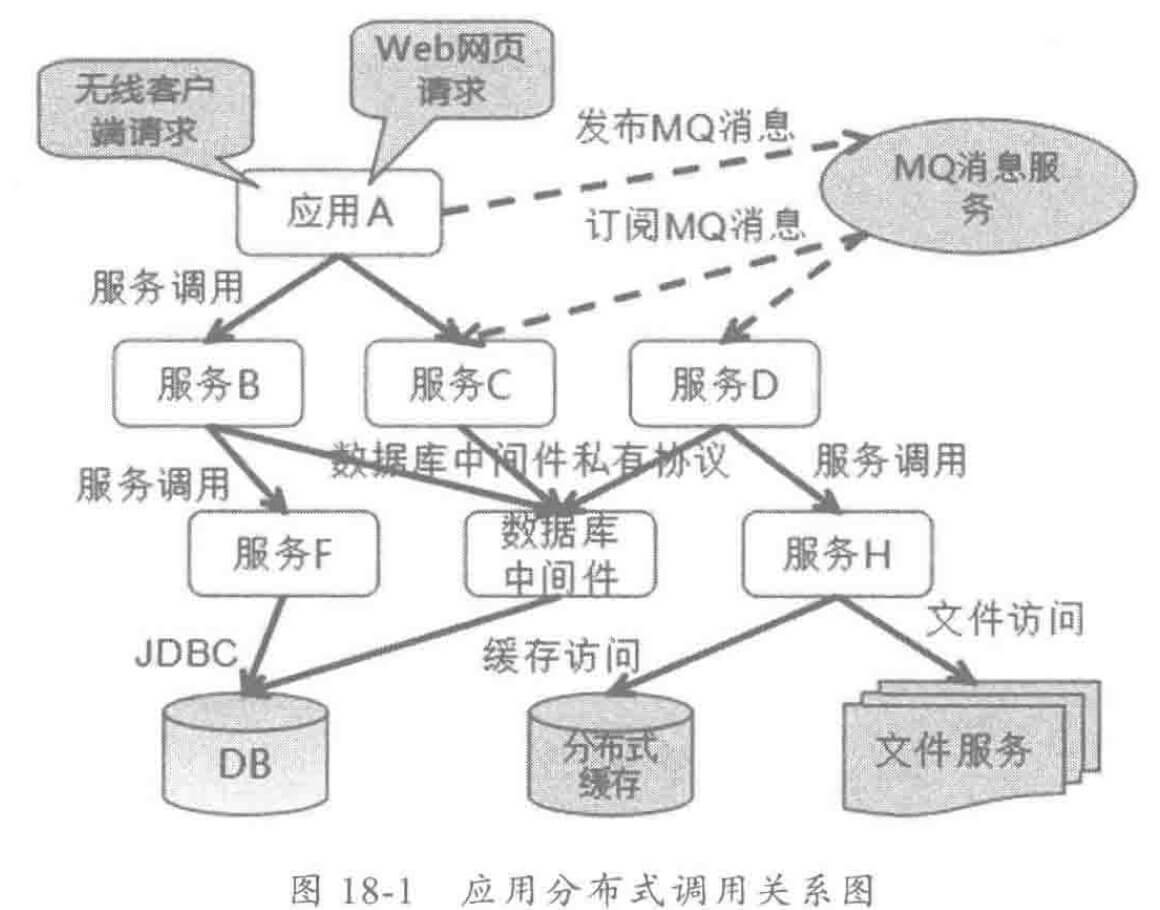
1.1 故障的快速定界定位
传统应用软件发生故障时,往往通过接口日志手工从故障节点采集日志进行问题分析定位,分布式服务化之后,一次业务调用可能涉及到后台上百次服务调用,每个服务又是集群组网,传统人工到各个服务节点人肉搜索的方式效率很低。
希望能够通过调用链跟踪,将一次业务调用的完整轨迹以调用链的形式展示出来,通过图形化界面查看每次服务调用结果,以及故障信息。
通过在业务日志中增加调用链 ID ,可以实现业务日志和调用链的动态关联。通过调用链进行快速故障定界,然后通过 ID 关联查询,可以快速定位到业务日志相关信息。
1.2 调用路径分析
通过对调用链调用路径的分析,可以识别应用的关键路径:应用被调用得最多的入口、服务是哪些,找出服务的热点、耗时瓶颈和易故障点。同时为性能优化、容量规划等提供数据支撑。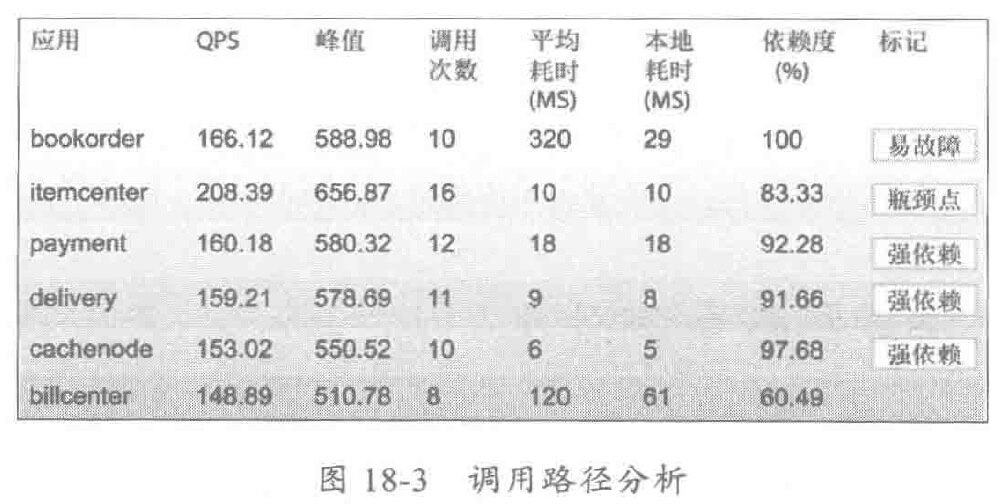
1.3 调用来源和去向分析
通过调用去向分析,可以对服务的依赖关系进行梳理:
- 应用直接和间接依赖了哪些服务。
- 各层次依赖的调用时延、QPS、成功率等性能 KPI指标。
- 识别不合理的强依赖,或者冗余依赖,反向要求开发进行依赖解耦和优化。
通过对调用来源进行 TOP排序,识别当前服务的消费来源,以及获取各消费者的 QPS、平均时延、出错率等,针对特定的消费者,可以做针对性治理,例如针对某个消费者的限流降级、路由策略修改等,保障服务的 SLA。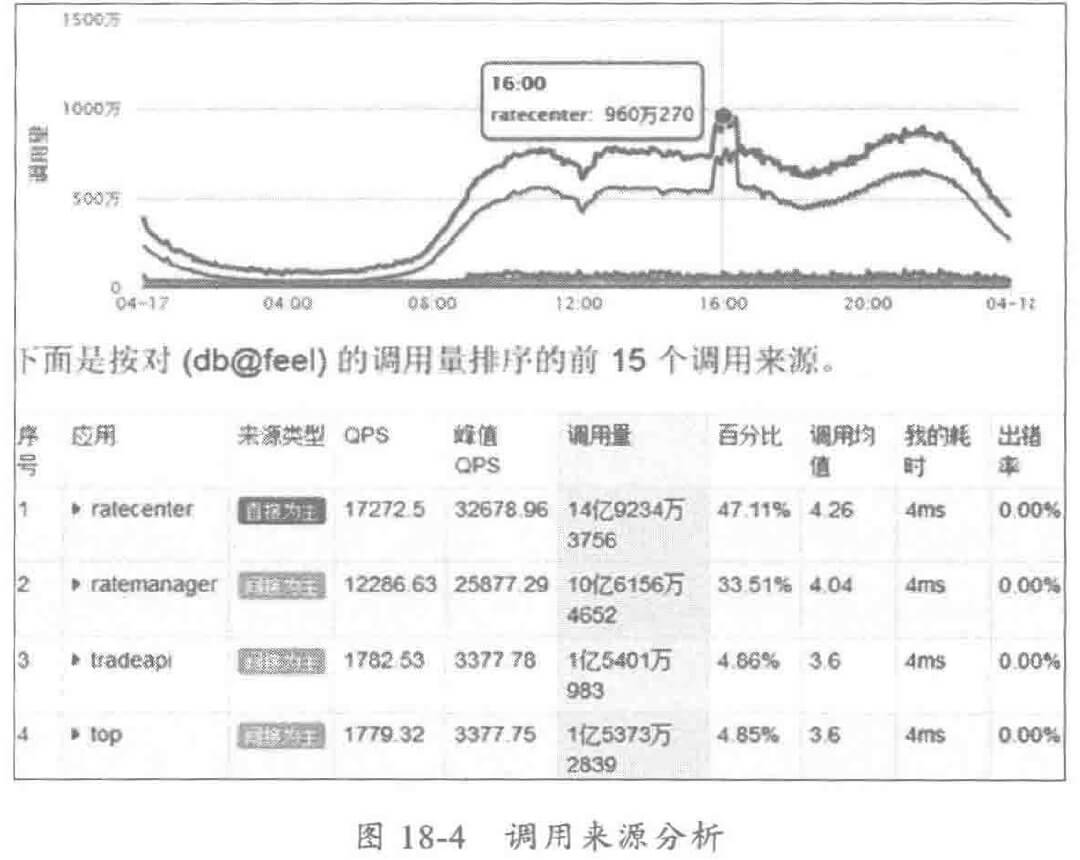
2 分布式消息跟踪系统设计
消息跟踪系统的核心就是调用链:每次业务请求都生成一个全局唯一的 TraceID,通过跟踪 ID将不同节点间的日志串接起来,形成一个完整的日志调用链,通过对调用链日志做实时采集、汇总和大数据分析,提取各种维度的价值数据,为系统运维和运营提供大数据支撑。
2.1 系统架构
分布式消息跟踪系统的整体架构如下,由四部分组成: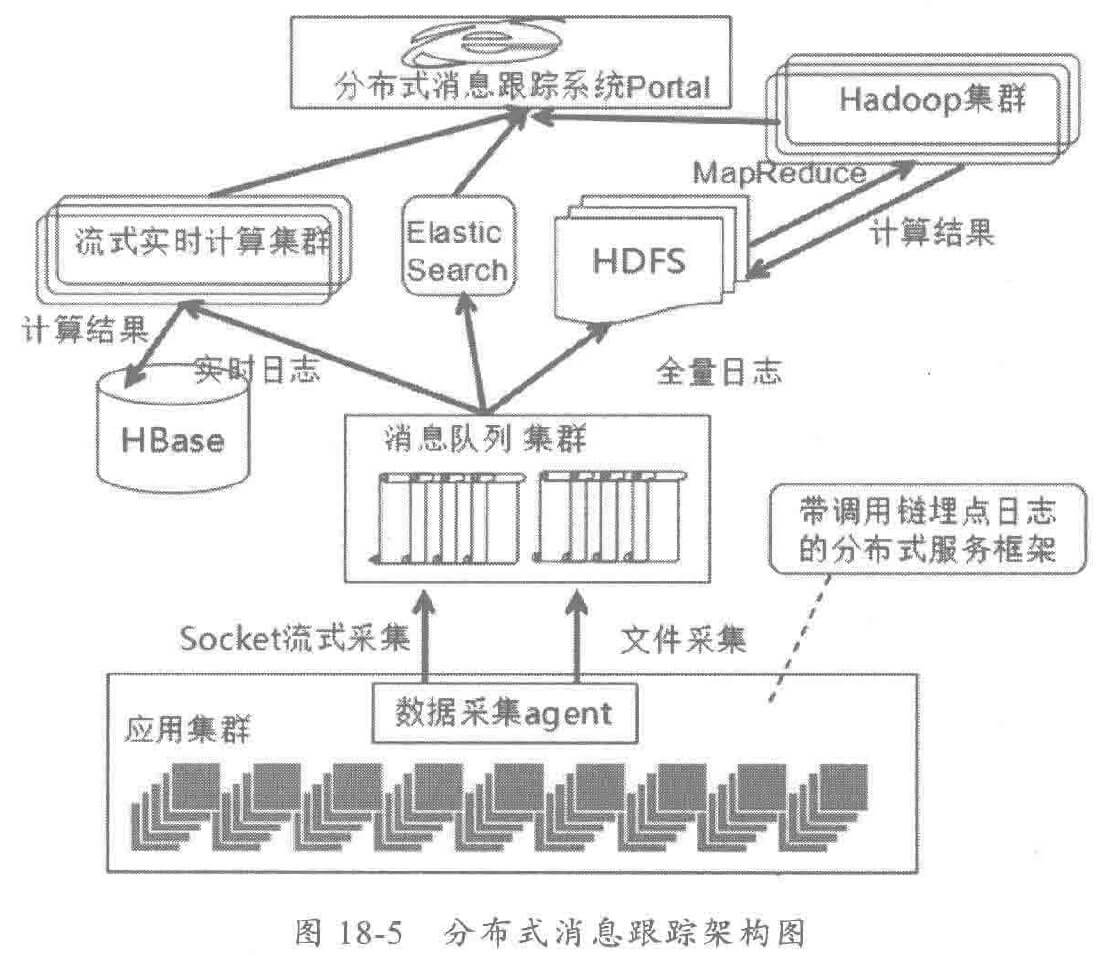
- 调用链埋点日志生成
- 分布式采集和存储埋点日志
- 在线、离线大数据计算,对调用链数据进行分析和汇总
- 调用链的界面展示、排序和检索等
2.2 埋点日志
埋点就是分布式消息跟踪系统在当前节点的上下文信息,埋点可以分为两类:
- 客户端埋点,客户端发送请求消息时生成的调用上下文,通常包括 TraceID、调用方 IP、调用方接口或者业务名称、调用的发起时间、被调用的服务名、方法名、IP 地址和端口等信息。
- 服务端埋点,服务端返回应答消息时在当前节点生成的上下文,包括 TraceID、调用方上下文信息、服务端处理的耗时、处理结果等信息。
埋点日志的实现,通常会包含如下几个功能:
- 埋点规范,主要用于业务二次定制开发和第三方中间件/系统对接。
- 埋点日志类库,服务生成埋点上下文,打印埋点日志等。
- 中间件预置埋点功能,应用不需要开发任何业务代码即可直接使用,也可以通过埋点类库将应用自身的业务字段携带到调用链上下文中,例如终端类型、手机号等。
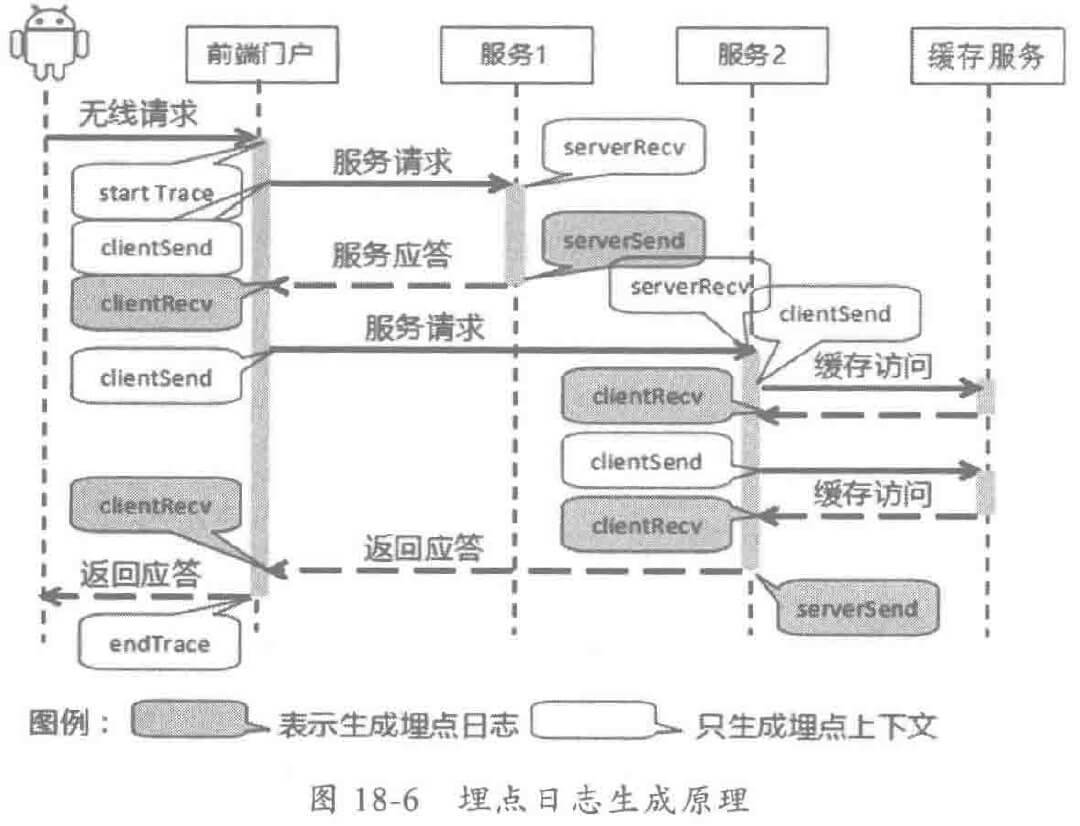
消息跟踪 ID 通常由调用首节点负责生成(各种门户 Portal),本 JVM 之内通常线程上下文传递 TraceID,跨节点传递时,往往通过分布式服务框架的显式传参传递到下游节点,实现消息跟踪上下文的跨节点传递。
埋点日志上下文通常需要包含如下内容:
- TraceID、RPCID、调用的开始时间、调用类型、协议类型、调用方 IP 和端口、被调用方 IP 和端口、请求方接口名、被调用方服务名等信息。
- 调用耗时、调用结果、异常信息、处理的消息报文大小等。
- 可扩展字段,通常用于应用扩展埋点上下文信息。
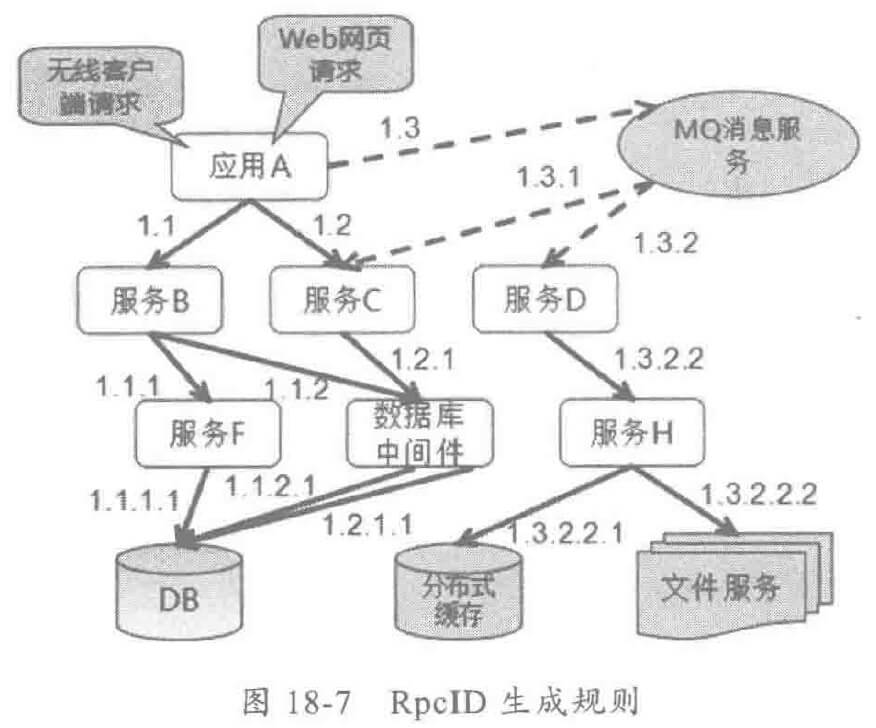
消息跟踪ID(TraceID)是关联一次完整应用调用的唯一标识,需要在整个集群内唯一,它的取值策略有很多,例如 UUID,UUID(Universally Unique Identifier)即全局唯一标识符,是指在一台机器上生成的数字,它保证对在同一时空中所有机器都是唯一的。按照开发软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片 ID 码和许多可能的数字。由以下几部分组合:当前日期和时间(UUID 的第一部分与时间有关,如果你在生成一个 UUID 之后,过几秒又生成一个 UUID,则第一部分不同,其余相同),时钟序列,全局唯一的 IEEE 机器识别号(如果有网卡,从网卡获得,没有网卡以其它方式获得),UUID 的唯一缺陷在于生成的结果串会比较长。
- IP 地址和端口:调用发起方和被调用方 IP 地址、端口号
- 时间戳:埋点上下文的生成时间
- 顺序号:标识链路传递序列的 RpcID
- 进程号:应用的进程 ID
- 随机数:例如可以选择 8 位数的随机数
原理上,埋点日志比较简单,实现起来并不复杂。但是在实际工作中,埋点日志也会面临一些技术挑战,举例如下:
- 异步调用:业务服务中直接调用 MQ 客户端,或者其它中间件的客户端时,可能会发生线程切换,通常线程上下文传递的埋点信息丢失,MQ 客户端会认为自己是首节点,重新生成 TraceID,导致调用链串接不起来。
- 性能影响:由于 Java I/O 操作通常都是同步的,如果磁盘的 WIO 比较高,会导致写埋点日志阻塞应用线程,导致时延增大。频繁地写埋点日志,也会占用大量的 CPU、带宽等系统资源,影响正常业务的运行。
对于线程切换问题,在切换时需求做线程上下文的备份,将埋点上下文复制到切换的线程上下文中,即可解决问题。
频繁写埋点日志影响性能问题,可以通过如下措施改善该问题:
- 支持异步写日志,防止写埋点日志慢阻塞服务线程。具体实现上可以通过采用 log4j 的异步 Appender、独立的日志线程池甚至是 JDK1.7 之后提供的异步文件操作接口。
- 提供可灵活配置的埋点采样率,控制埋点日志量。
- 批量写日志,日志流控机制。
2.3 采样率
对于高 QPS 的应用,服务调用埋点本身的性能损耗也不容忽视,为了解决 100% 全采样的性能损耗,可以通过采样率来实现埋点低损耗的目标。
采样包括静态采用和动态采样两种,静态采样就是系统上线时设置一个采样率,无论负载高低,均按照采样率执行。动态采样率根据系统的负载可以自动调整,当负载比较低的时候可以实现 100% 全采样,在负载非常重时甚至可以降低到 0 采样。
是否采样由调用链的首节点进行判断,首节点根据采样率算法,决定某个业务访问是否采样,如果需要采样,则把采样标识、TraceID 等采样上下文发送到下游服务节点,下游服务节点根据采样标识做判断,如果采样则获取调用链上下文并补充完整,反之则不埋点。
2.4 采集和存储埋点日志
开源 的 ELK,原理如下: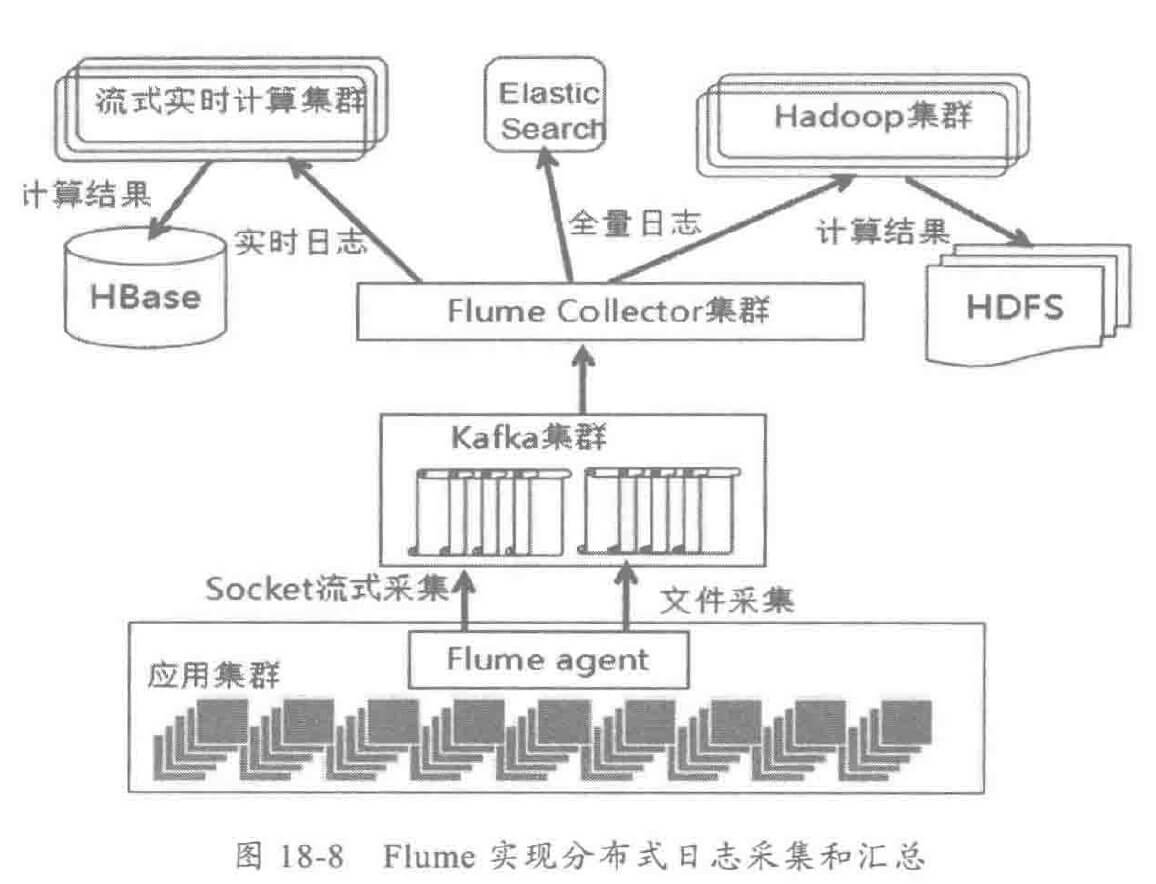
需要考虑:
- 采集过程中发生宕机,如何在中断点恢复采集。
- 采集过程中如果埋点日志发生了文件切换(例如达到单个日志文件 100MB 上限之后,自动进行文件切换),如何正确应对。
- 采集 Channel 发生网络故障,导致采集的日志部分发送失败,故障恢复之前,日志如何缓存,故障恢复之后,已采集尚未发送的日志如何发送。
- 考虑到性能,是不是单条采集、批量发送性能更优。
3 个人总结
通过对业务流程的记录和采集,进行在线和离线的大数据计算,数据清洗获取有价值的数据。同时还能根据运行情况做服务的调整。