相对于传统的本地 Java API 调用,跨进程的分布式服务调用面临的故障风险更高:
- 网络类故障:链路闪断、读写超时等。
- 序列化和反序列化失败。
- 畸形码流。
- 服务端流控和拥塞保护导致的服务调用失败。
- 其它异常。
对于应用而言,分布式服务框架需要具备足够的健壮性,在平台底层能够拦截并向上屏蔽故障,业务只需要配置容错策略,即可实现高可靠性。
1 服务状态监测
在分布式服务调用时,某个服务提供者可能已经宕机,如果采用随机路由策略,消息会继续发送给已经宕机的服务提供者,导致消息发送失败。为了保证路由的正确性,消费者需要能够实时获取服务提供者的状态,当某个服务提供者不可用时,将它从缓存的路由表中删除掉,不再向其发送消息,直到对方恢复正常。
1.1 基于服务注册中心状态监测
以 ZooKeeper 为例,ZooKeeper 服务端利用与 ZooKeeper 客户端之间的长链接会话做心跳检测。
1.2 链路有效性状态监测机制
分布式服务框架的服务消费者和提供者之间默认往往采用长链接,并且通过双向心跳检测保障链路的可靠性。
在一些特殊的场景中,服务提供者和注册中心之间网络可达,服务消费者和注册中心网络也可达,但是服务提供者和消费者之间网络不可达,或者服务提供者和消费者之间链路已经断连。此时,服务注册中心并不能检测到服务提供者异常,但是如果消费者仍旧向链路中断的提供者发送消息,写操作将会失败。
为了解决该问题,通常需要使用服务注册中心检测 + 服务提供者和消费者之间的链路有效性检测双重检测来保障系统的可靠性,它工作原理如下: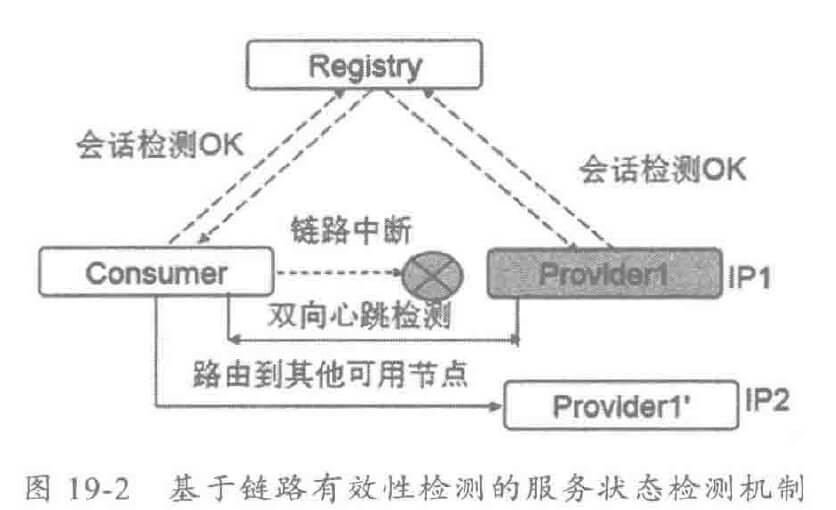
当消费者通过双向心跳检测发现链路故障之后,会主动释放链接,并将对应的服务提供者从路由缓存表中删除。当链路恢复之后,重新将恢复的故障服务提供者地址信息加入地址缓存表中。
2 服务健康度监测
在集群组网环境下,由于硬件性能差异、各服务提供者的负载不均等原因,如果采用随机路由分发策略,会导致负载较重的服务提供者不堪重负被压垮。
利用服务的健康度监测,可以对集群的所有服务实例进行体检,根据体检加过对健康度做打分,得分较低的亚健康服务节点,路由权重会被自动调低,发送到对应节点的消息会少很多。这样实现“能者多劳、按需分配”,实现更合理的资源分配和路由调度。
服务的健康度监测通常需要采集如下性能 KPI 指标:
- 服务调用时延。
- 服务 QPS。
- 服务调用成功率。
- 基础资源使用情况,例如堆内存、CPU 使用率等。
原理如下: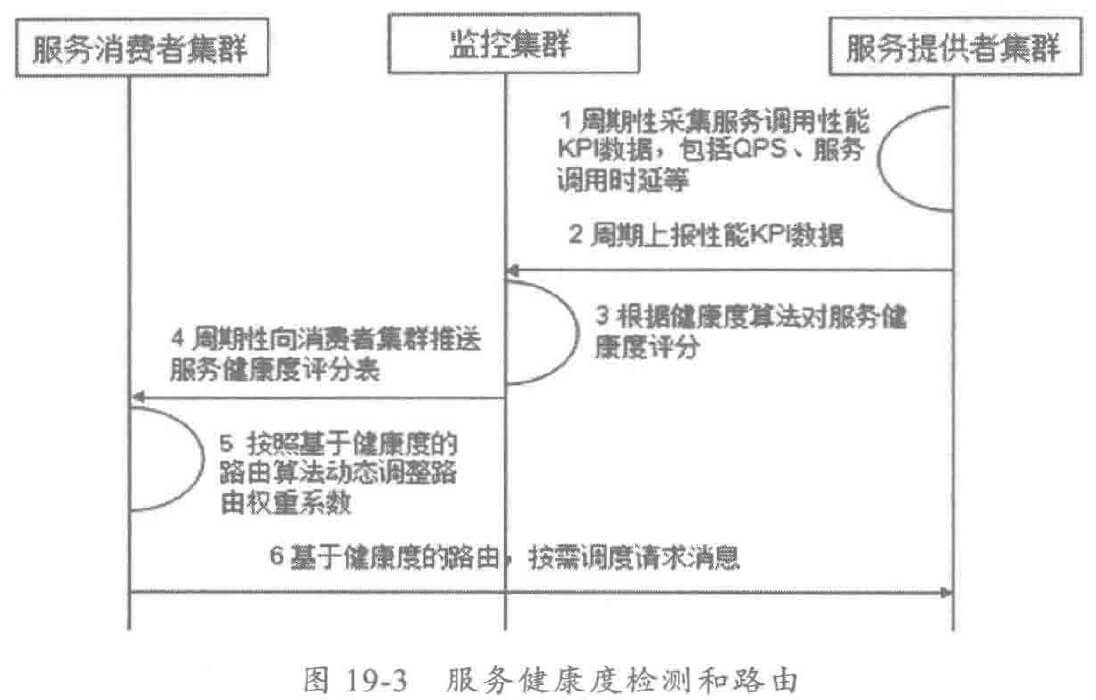
3 服务故障隔离
分为四个层次:
- 进程级故障隔离
- VM 级故障隔离
- 物理机故障隔离
- 机房故障隔离
3.1 进程级故障隔离
个人理解为线程级。即通过将服务部署到不同的线程池实现故障隔离。对于订单、购物车等核心服务可以独立部署到一个线程池中,与其它服务做线程调度隔离。对于非核心服务,可以合设共享同一个/多个线程池,防止因为服务数过多导致线程数过度膨胀。
服务发布的时候,可以指定服务发布到哪个线程池中,分布式服务框架拦截 Spring 容器的启动,解析 XML 标签,生成服务和线程池的映射关系,通信框架将解码后的消息投递到后端时,根据服务名选择对应的线程池,将消息投递到映射线程池的消息队列中。
原理图如下: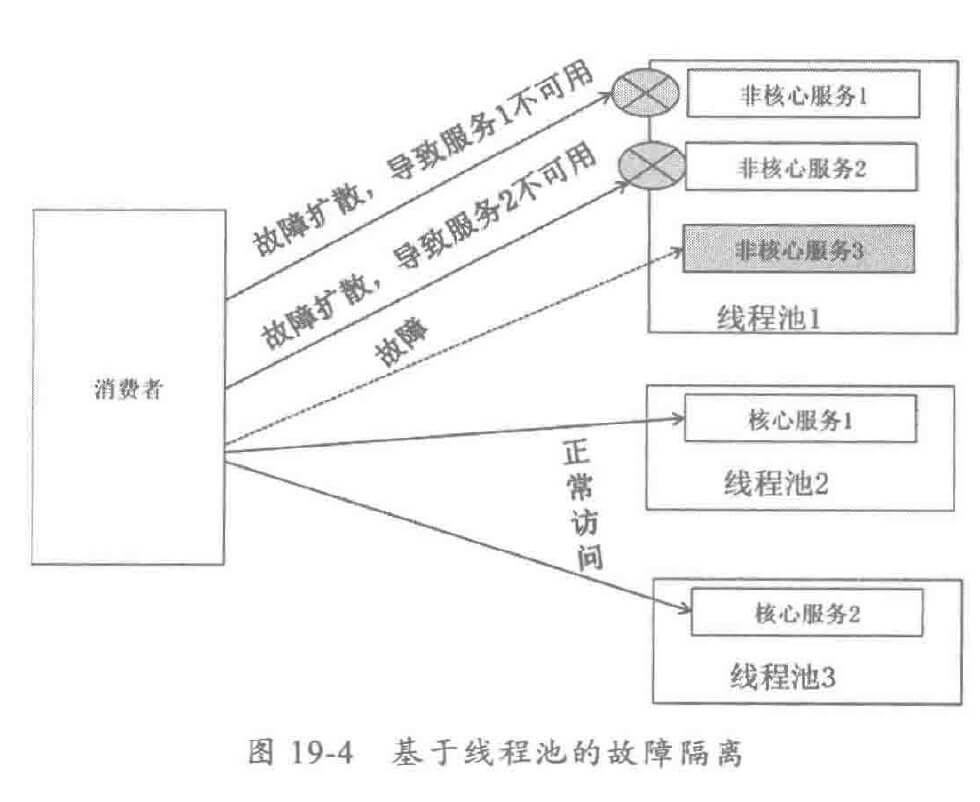
如果故障服务发生了内存泄漏异常,它会导致整个进程不可用。
3.2 VM 级故障隔离
将基础设施层虚拟化、服务化,将应用部署到不同的 VM 中,利用 VM 对资源层的隔离,实现高层次的服务故障隔离,工作原理如下: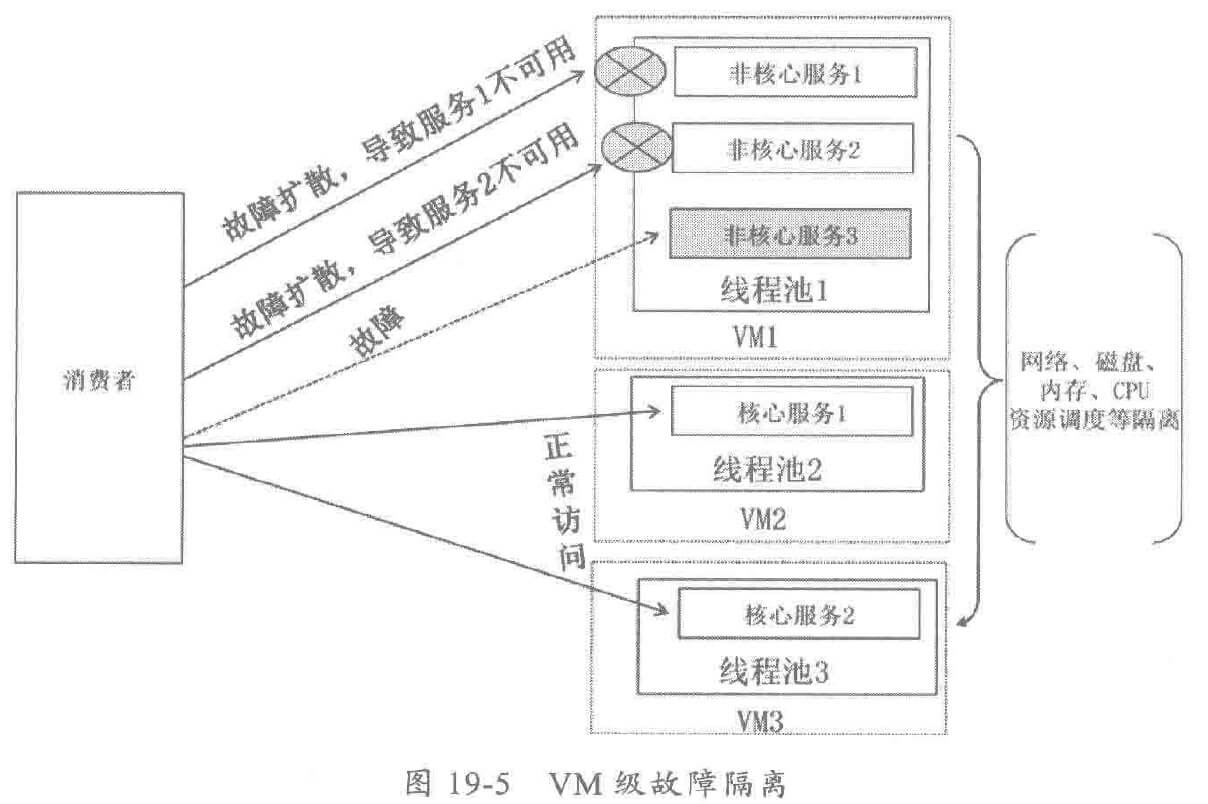
3.3 物理机故障隔离
当组网规模足够大、硬件足够多的时候,硬件的故障就由小概率事件转变为普通事件。如何保证在物理机故障时,应用能够正常工作,是一个不小的挑战。
利用分布式服务框架的集群容错功能,可以实现位置无关的自动容错,工作原理如下: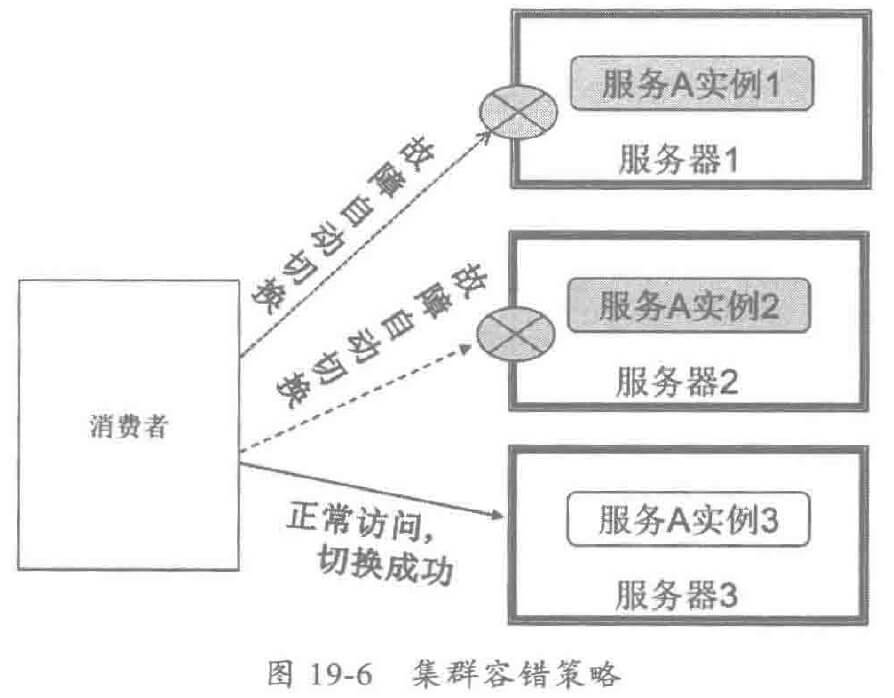
如果要保证当前服务器宕机时不影响部署在上面运行的服务,需要采用分布式集群部署,而且要采用非亲和性安装:即服务实例需要部署到不同的物理机上,通常至少需要 3 台物理机,假如单台物理机的故障发生概率为 0.1 %,则 3 台同时发生故障的概率为 0.001%,服务的可靠性将会达到 99.999%,完全可以满足大多数应用场景的可靠性要求。
物理机故障重启之后,通过扩展插件通知 Watch Dog 重新将应用拉起,应用启动时会重新发布服务,服务发布成功之后,故障服务器节点就能重新恢复正常工作。 ·`
3.4 机房故障隔离
同城容灾时,都需要使用多个机房,下面针对跨机房的容灾和故障隔离方案进行探讨。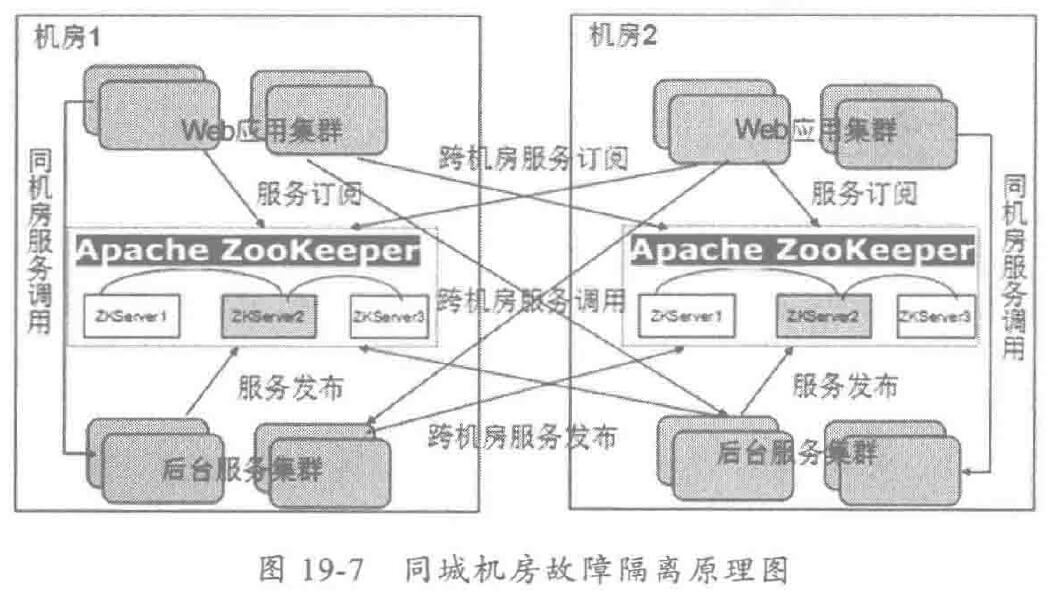
机房1 和机房2 对等部署了2套应用集群,每个机房部署一套服务注册中心集群,服务订阅和发布同时针对两个注册中心,对于机房1 或者机房2 的 Web 应用,可以同时看到两个机房的服务提供者列表。
理由时,优先访问同一个机房的服务提供者,当本机房的服务提供者大面积不可用或者全部不可用时,根据跨机房路由策略,访问另一个机房的服务提供者,待本机房服务提供者集群恢复到正常状态之后,重新切换到本机房访问模式。
当整个机房宕机之后,由前端的 SLB\F5 负载均衡器自动将流量切换到容灾机房,由于主机房整个瘫掉了,容灾机房的消费者通过服务状态监测将主机房的所有服务提供者从路由缓存表中删除,服务调用会自动切换到本机房调用模式,实现故障的自动容灾切换。
上面的方案需要分布式服务框架支持多注册中心,同一个服务实例,可以同时注册到多个服务注册中心中,实现跨机房的服务调用。两个机房共用一套服务注册中心也可以,但是如果服务注册中心所在的机房整个宕掉,则分布式服务框架的服务注册中心将不可用。已有的服务调用不受影响,新的依赖服务注册中心的操作江辉失败,例如服务治理、运行期参数调整、服务的状态监测等功能将不可用。
4 其它可靠性特性
4.1 服务注册中心
服务注册中心需要采用对等集群设计,任意一台宕机之后,需要能够自动切换到下一台可用的注册中心。例如 ZooKeeper ,如果某个 Leader 节点宕机,通过选举算法会重新选举出一个新的 Leader,只要集群组网实例数不小于 3,整个集群就能够正常工作。
4.2 监控中心
监控中心集群宕机之后,只丢失部分采样数据,依赖性能 KPI 采样数据的服务健康度监测功能不能正常使用,服务提供者和消费者依然能够正常运行,业务不会中断。
4.3 服务提供者
某个服务提供者宕机之后,利用集群容错策略,会舱室不同的容错恢复手段,例如使用 FailOver 容错策略,自动切换到下一个可用的服务,直到找到可用的服务为止。
如果整个服务提供者集群都宕机,可以利用服务放通、故障引流、容灾切换等手段。
5 个人总结
任何假设的宕机情况都会出现,解决手段不外乎:
- 对等集群(例如跨机房)。
- 服务放通(远程错误直接切换为本地调用)。
- 隔离。