0. 背景
临近双11,公司对所有的接口都使用阿里云的全链路压测工具做压测,比如首页的 TPS 是3000,支付的 TPS 是 60,根据不同的接口做不同的策略。其中数值是根据平时的5倍计算得出的。
这篇博文就是使用阿里云的 arms 监控(APM的一种,类似 skywalking,可以查看请求的每个链路)以及 PTS(做压测的一种工具)对两次压测的优化总结。
待拆解项目机器集群A:48台,配置为4核8G
本项目机器集群B:6台,配置为4核8G
由于压测时正在在拆解服务中,因此大部分接口在A集群中。
A 集群20%的接口通过 RPC 请求到 B,80%的接口通过发送消息跟 B 交互。
数据库配置:1写5读,配置较高,只在主库操作。在压测过程中主库 CPU 基本属于较为稳定。
ONS:发送、接收消息总 TPS 为 5000,在压测过程中基本还未达到该阈值。总 TPS 稳定在 40(即发、接消息各20)。
Redis:4G两节点,不是瓶颈。
第三方请求接口主要有:支付的请求下单、通知回调、银行卡四要素验证等。
1. MySQL
使用 MySQL 的主要用途用于存储支付参数、支付结果等信息,主要是短查询和长写入,整个支付下单事务较长。
另外由于正在拆解服务,还没有将支付相关的数据库独立出来,因此项目的数据库性能会受到其它项目对数据库的影响,从而影响本项目的性能,这是没法避免的。
优化第一点是配置最大连接数:
查看最大连接数: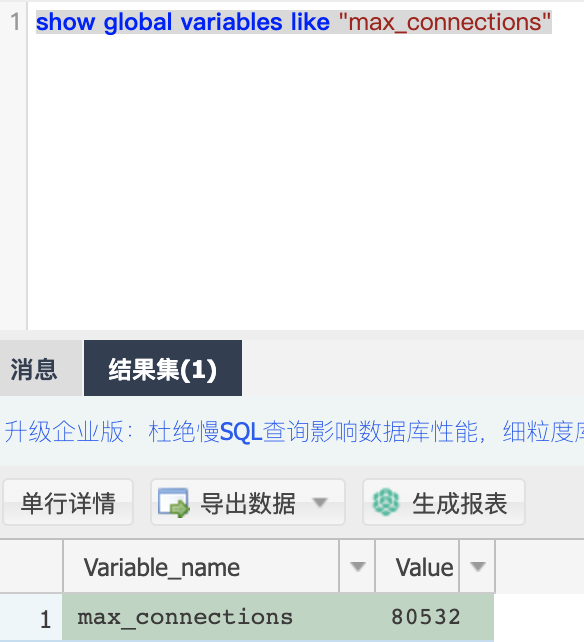
根据数据库能支撑的最大连接数,以及连接该数据库一共有几个项目,来设置平均每个项目的连接数,我这边设置从之前的 20 变更为 50。
那什么时候才知道是连接数的问题呢?其实当你在发现某个接口,它请求访问数据库的操作一共需要5s,但是你查看数据库的相关语句的时候,发现语句最慢也才耗时 1s,那这时你就需要怀疑是否是因为等待获取连接而耗费很大量的时间。
第二点是去掉多余的事务:
你仔细看了整个项目,从业务和技术角度上考虑过项目上是否有多余的事务注解吗?因为我就犯了这个错。
原来的某个服务 A 本来是个有更新操作的,优化后,将更新操作放到别处了,因此服务 A 里面只有一个查询,但是我忘记去掉该服务的 Transaction 注解,导致在压测的时候,该服务的响应时间是1分钟,查看链路发现是一个 select 语句就1分钟!当去掉 Transaction 后变成了10ms!
2. ONS
ons 是 rocketmq 的商业版,使用基本和 rocketmq 一致。但是我个人觉得没有 rocketmq 好用,我之前公司使用自己搭建的 rocketmq,有问题基本debug,就能大概定位问题。但是 ons 是闭源的,只能提工单到他们的工作人员,等待反馈。不过 ons 适合刚初创企业,没有多余能力去使用 rocketmq。不可否认的是,当业务发展量到了一定程度,使用 rocketmq 是必然的结果!
优化第一点:消息能否延迟?
我在控制台观察消息的生产消费量,支付相关的消息平时相对来说不是很多,然后再看压测时候的消息大致是多少,当时在压测的时候消息使用的是普通消息,导致某个时间消息堆积消费很高,CPU飙升,没有达到削峰的功能!后来在分析该业务后,发现该业务可以接受大概30s的延迟,因此使用了随机延迟消息,平摊到 30s 内做处理,达到了削峰填谷的功能,将 CPU 稳定在了 15%,提升很大。
但是这里有个疑问,我之前了解 rocketmq 知道它使用延迟消息是使用延迟级别的队列实现,即:你有几个延迟级别,就需要多少个额外的队列,但是在 ons,我使用的随机延迟消息,理论上ons那就支持了无限的延迟队列,但是这是不可能的,因此它肯定有自己更好的延迟队列实现!
另外也可以参考消息的最佳实践:
一个微服务用一个 GroupId,项目内部一级业务类型,使用 Topic 区分。二级业务使用 TAG 区分。例如我这边的支付相关消息使用 Pay_Topic,下面一些比如退款或转账的具体业务使用 TAG 区分,具体的最佳实践参考文档:https://help.aliyun.com/document_detail/95837.html?spm=a2c4g.11174283.6.624.3a945793jfF9XT
其中一个插曲,是关于消息负载的问题,由于阿里他们消息负载有问题(他们也承认了,正在优化),因此有经常某台机器负载堆积消息尤其严重,而有的机器又很空闲。他们答应尽快解决,我这边暂时使用 sentinel 做消息的限流。这也侧面验证其实自建消息队列是很有必要的,至少在消息的负载上,我们可以透明化,一是消息到队列的负载,二是队列到消费者的负载,都可以根据业务情况精准控制。
3. Redis
关于 Redis 我这边并没有使用很多,因为支付基本都是走的主库,需要实时性,当然有部分的支付相关边缘业务,查询较多,才会考虑使用 Redis 缓存,引入 Redis 还是有一定的技术成本,使用不当会弄巧成拙。
我在项目中唯一使用 Redis 的地方是用来保证消息消费的幂等性。
由于消息发送方是使用的 ons-client 老的版本,有一些BUG,但是 one-client 新的版本和老的版本部门协议又有不同,没法兼容。而发送方项目由于很多项目都做了依赖,改动 one-client 版本成本太大。因此要解决这个 BUG,需要从我自己项目入手。
该 BUG 表现为 exactly-once 的状态变更 bug。ons 的 exactly-once 原理如下:消费端建一张消息消费表,并在代码注入使用它的 MQDataSouce,该 datasource 会在消息消费前后做切面,加入了消费状态的变更和判定,例如:消费状态未消费、消费中、消费完成、消费异常等,而状态的变更写入数据库是和业务的数据库属于同一个事务,从而保证了消息的幂等————通过额外一个消费表记录来实现。但是由于有 BUG,这个状态判定有个小问题,因此我在消费业务代码最外层加入了 Redis,它实现了类似的功能,对同一个 MessageKey 记录消费状态,来实现消息的去重。那我为什么不使用数据库表来实现呢?因为方便。唯一的问题是 Redis 挂掉的问题,或者说是不一致问题。但是说实话,Redis 挂掉的几率基本和 MySQL 挂掉几率基本一样,因为我们都是使用的阿里云集群机器。
4. 内部项目接口
我们内部项目间互相调用使用 dubbo 调用,优化基本集中在 dubbo 配置上。
第一个是将 threadpool 将 cached 改为 fixed,数量默认为 200,这是参考了 arms 监控中的线程池变化设定的,而且机器性能也好,不过还需要下次压测查看结果,毕竟线程上下文切换也不知道损耗多少。
第二个是超时时间,我这边设置为 3000 ms(默认 1000 ms),另外使用了 Redisson 做重复请求的锁,锁 3000 ms,避免多次点击,由于业务正在优化,某些业务还不支持幂等,重复请求会有点问题,基本在 3 秒内支付相关流程事务执行完,状态写入成功,就没什么大问题了。
第三个是 loadbalance 策略,修改为 leastactive
另外,因为我们用的 nacos 有个权重配置,不过这个我还没用,如果以后机器性能不均匀可以有个参考优化点。
5. 第三方接口
第三方接口慢,没法避免,而且有的付费接口是基于 TPS 购买的,因此必须要使用限流,不然返回都是错误,用 sentinel 的 callback 就很方便。其它类似的限流工具也差不多,根据漏桶算法,做 TPS 判定,也可以选择使用 RT 做限流,我根据情况来选择 TPS 还是 RT 限流。
6. JVM 优化
jvm 优化主要是参考的 https://opts.console.perfma.com/ ,原来的参数是:1
-server -Xms4096m -Xmx4096m -XX:NewSize=1024m -XX:MaxNewSize=1024m -XX:PermSize=512M -XX:MaxPermSize=512m
机器 4核8G,现在的参数调整为:1
-server -Xms5440M -Xmx5440M -Xmn1984M -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m
其中主要参考了压测时的堆栈内存变化,其中可以看出 10-22 的变化:
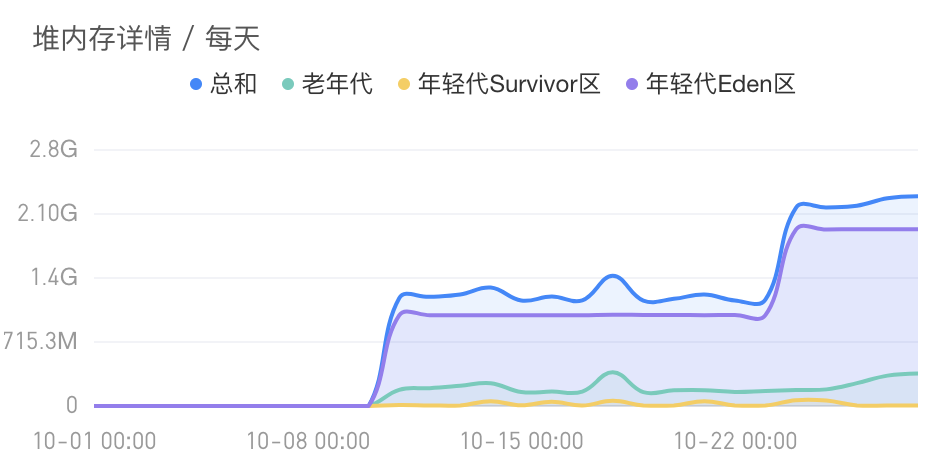
7. 后台任务分离
这个主要是将后台的定时任务全部迁入到一个专门的执行器项目,使用 xxl-job 来控制后台任务的执行,避免定时任务执行时的性能抖动,影响核心接口
8. 总结
- MySQL
慢SQL:但是我这边基本没有
连接数:这个根据阿里云 RDS 的性能和项目数做调整
是否有不必要的事务:检查去掉不必要的事务
死锁:其实死锁还是有,很难根本解决,只能说减少概率,这个之前也写死锁总结博文,但是因为这个暂时不是性能瓶颈,因为在之后会花时间再解决。
- 消息队列
消息是否可以接受延迟?如果可以,那么就随机延迟或者几个延迟级别随机选择。
机器消费消息是否负载均衡?如果不均衡,那么看是发消息到队列不均衡,还是队列到消费者不均衡。
- Redis
能不用缓存就不用缓存,如果性能问题,必须上缓存,那么要考虑缓存一致的问题,其实我在公司经常听到测试说,为什么这边修改但是用户那边还没改动,根本原因是,缓存在设计的时候不合理,乱用,而不考虑手动缓存失效,只能等待一定时间失效,这是不合理的。
Redis 不可用我暂时还没碰到,可能是使用量不大,不过性能抖动倒是碰到过,上家用的腾讯云,半夜会超时什么的,这个没办法,是提供商的问题。
- 内部接口
我们都是用 dubbo 做项目之间的请求
别人依赖你:别人依赖你的接口服务,那么尽量保证能异步就异步,日志通过 filter 拦截进出口的日志,方便调试。还有一个是关于 apm 的使用,我们使用了 skywalking,因此我加入了全局链路 token,方便跟踪某个请求,这个对定位问题很方便。自己提供的接口服务能加上限流控制就加上,关键时候设置限流有奇效。
你依赖别人:考虑当别人项目不可用时,你会发生什么,做异常的解决或者 callback 快速失败策略。还有请求超时时间以及负载策略的针对配置。
- JVM 优化
推荐参考 https://opts.console.perfma.com/ 输入自己的机器参数,自动给你生成相关参数,最后在实际中,观察项目的 JVM 堆栈实际情况,来做调整。
- 服务分离
前后台服务分离:后台定时任务分离独立为一个项目,提供给别人的接口服务独立为一个项目
核心业务分离:这个我没有实战,但是如果以后业务量膨胀,我会使用该方法,核心业务不能挂~