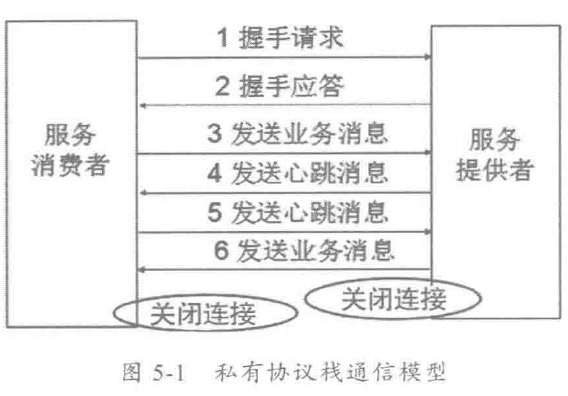
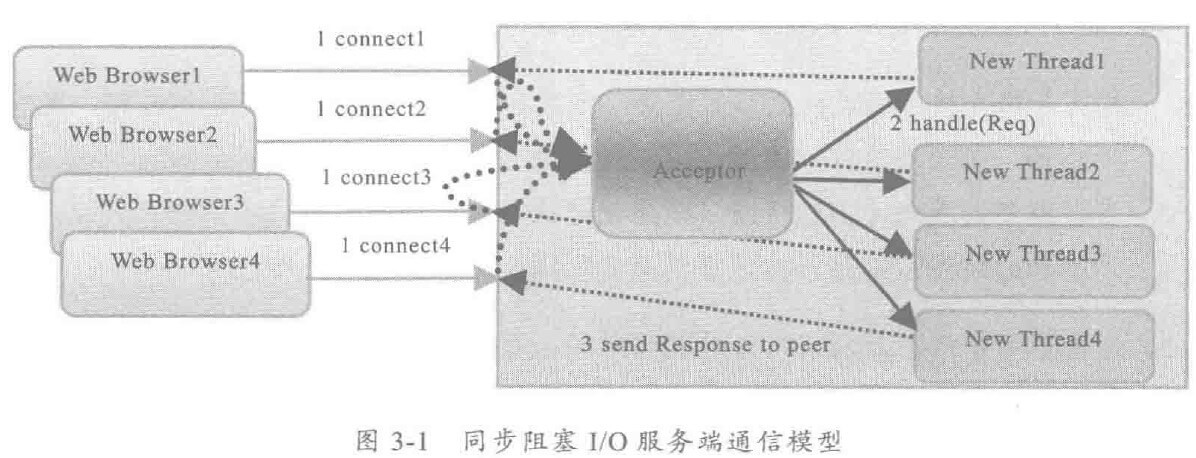
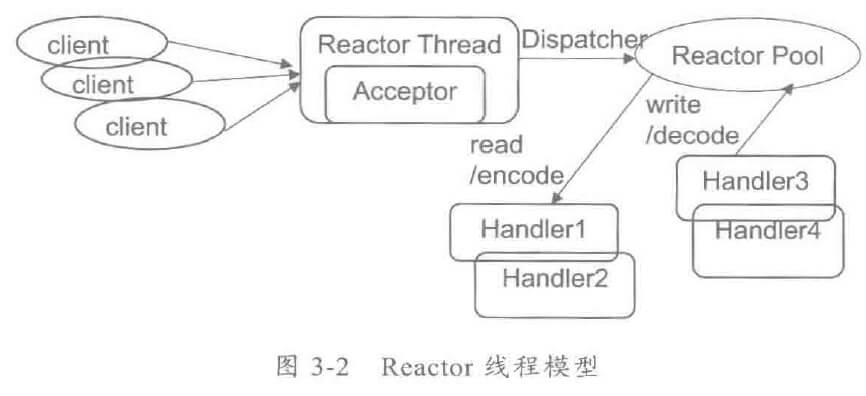
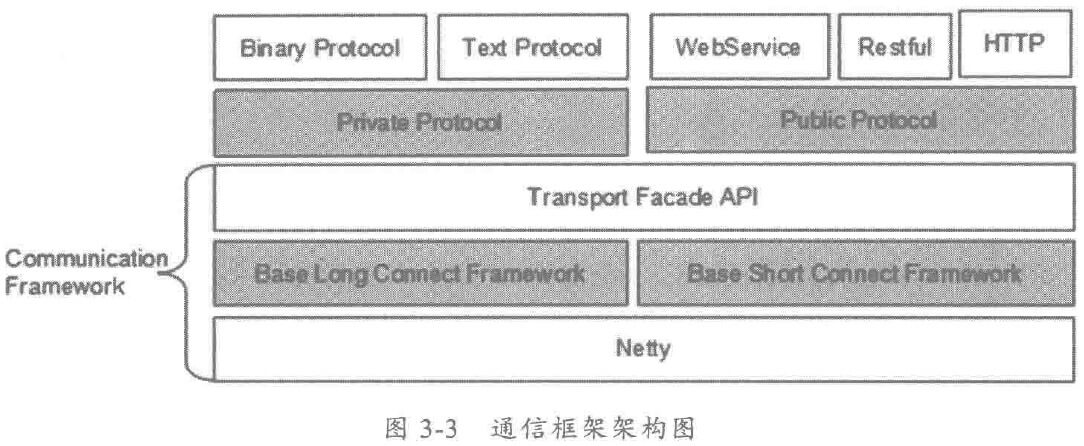
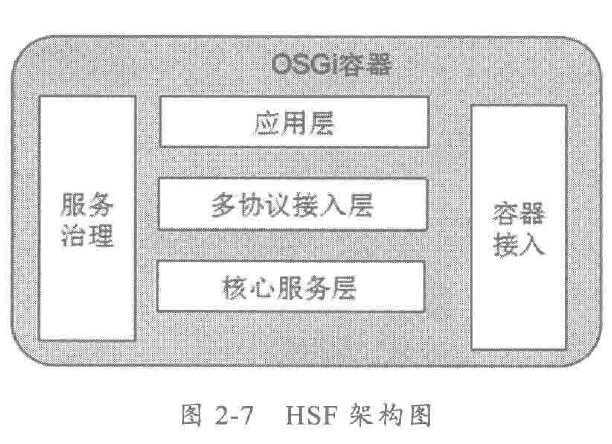
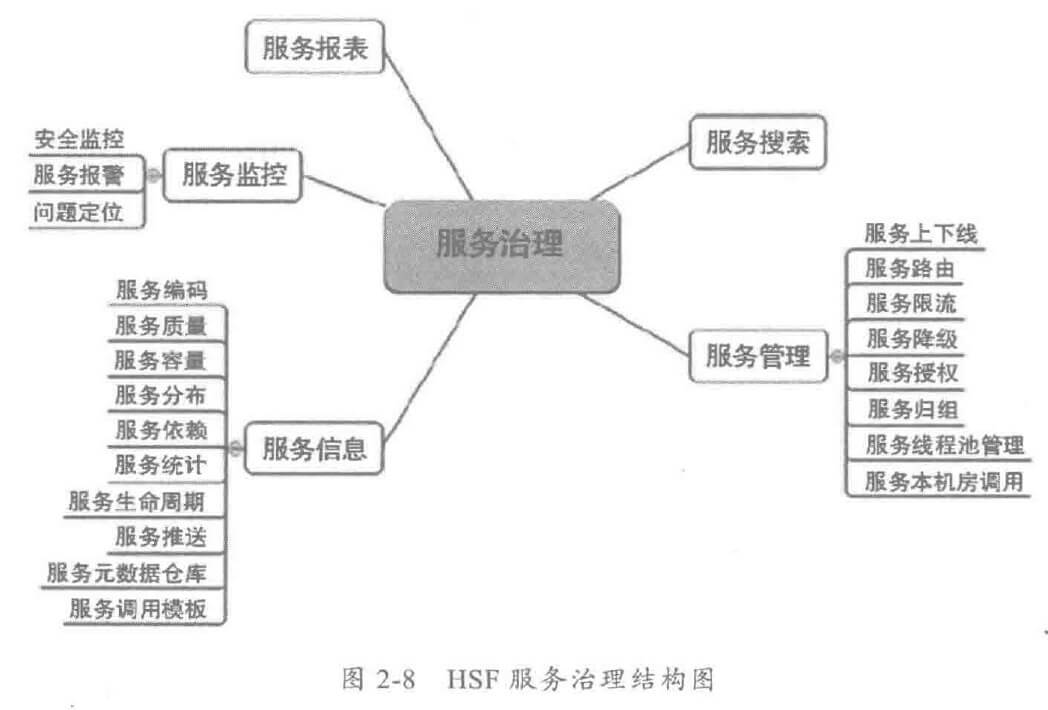
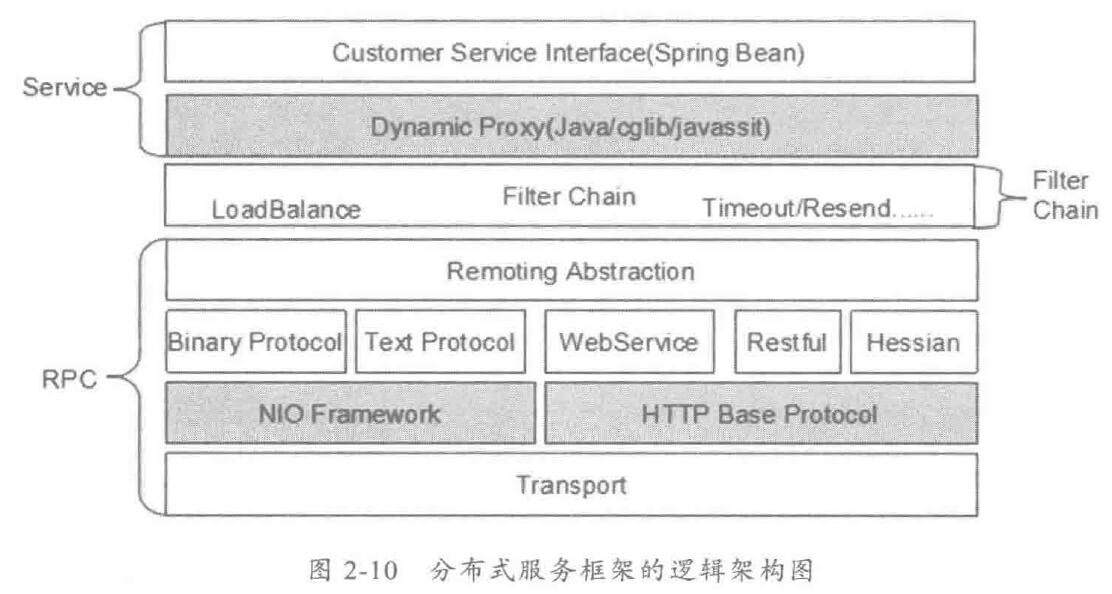
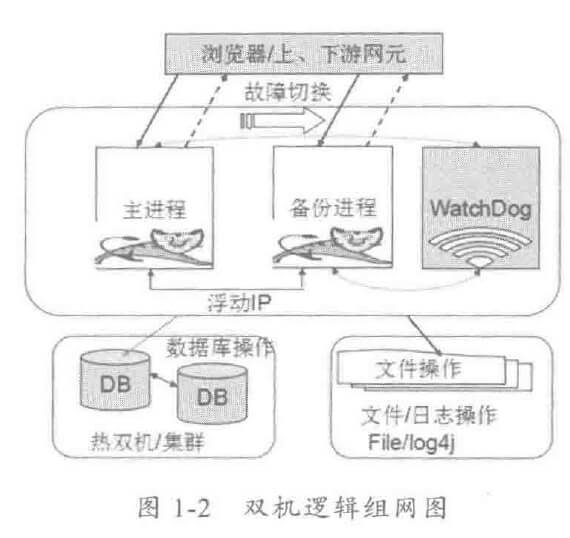
由于惯性思维,很多人会将传统 MVC架构/RPC架构的做法带入到分布式服务框架的架构设计中,其中有些思想存在误区,或者已经过时,它们会破坏分布式服务框架的架构品质。
1 几个误区
1.1 NIO 就是异步服务
NIO 只解决了通信层面的异步问题,跟服务调用的异步没有必然关系,也就是说,即便采用传统的 BIO 通信,依然可以实现异步服务调用,只不过通信效率和可靠性比较差。
下面对异步服务调用和通信框架的关系进行说明: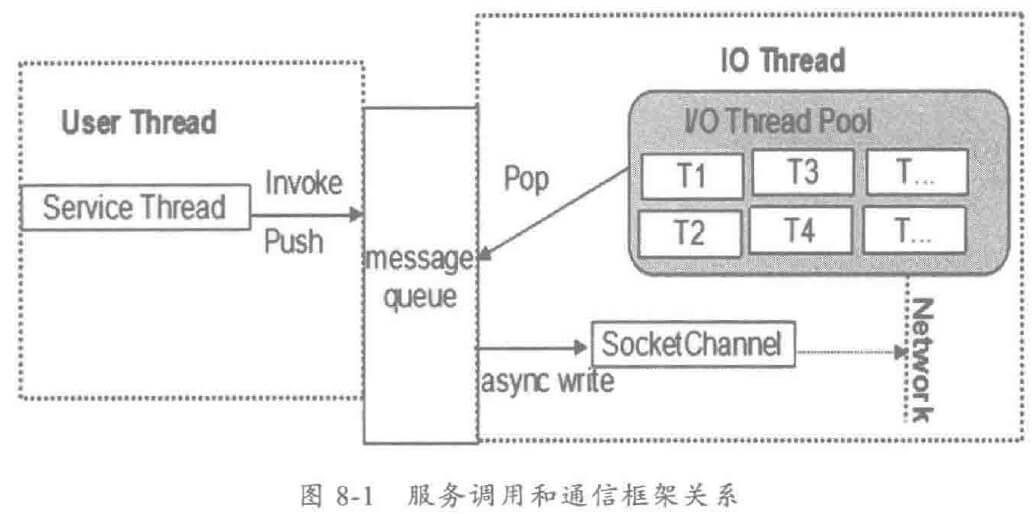
用户发起远程服务调用之后,经历层层业务逻辑处理、消息编码,最终序列化后的消息会被放入到通信框架的消息队列中。业务线程可以选择同步等待、也可以选择直接返回,通过消息队列的方式实现业务层和通信层的分离是比较成熟、典型的做法。
采用 NIO还是 BIO对上层的业务是不可见的,双方的汇聚点就是消息队列。业务线程将消息放入到发送队列中,可以选择主动等待或者立即返回,跟通信框架是否是 NIO 没有任何关系。
1.2 服务调用天生就是同步的
服务调用主要有两种模式:
- OneWay 模式:只有请求,没有应答,例如通知消息。
- 请求-应答模式:一请求,一应答的模式,这种模式最常用。
OneWay 模式的服务调用由于不需要返回应答,因此很容易被设计成异步的:消费者发起远程服务调用之后,立即返回,不需要同步阻塞等待应答。
对于请求-应答模式,可以利用 Future-Listener 机制来实现异步服务调用。从业务角度看,它的效果与同步等待等价,但是从技术角度来看,可以保证业务线程在不同步阻塞的情况下实现同步等待的效果,执行效率更高。
1.3 异步服务调用性能更高
复杂的场景,异步服务调用会更高,越复杂的场景,异步服务调用优势越大。
2 服务调用方式
2.1 同步服务调用
没什么可说的,只是需要注意设置用户线程等待超时时间。
2.2 异步服务调用
基于 JDK的 Future机制,异步服务调用的工作原理如下: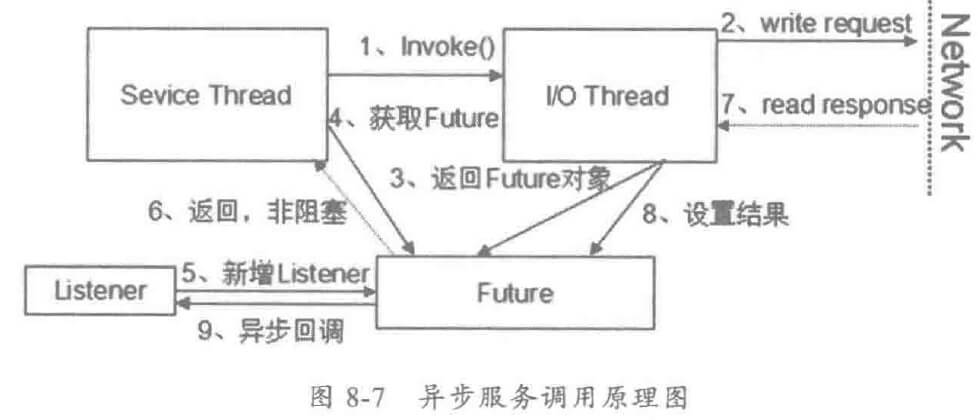
- 消费者调用服务端发布的接口,接口调用由分布式服务框架包装成动态代理,发起远程服务调用。
- 通信框架异步发送请求消息,如果没有发生 I/O异常,返回。
- 请求消息发送成功后,I/O 线程构造 Future 对象,设置到 RPC上下文中。
- 用户线程通过 RPC上下文获取 Future对象。
- 构造 Listener 对象,将其添加到 Future中,用于服务端应答异步回调通知。
- 用户线程返回,不阻塞等待应答,
- 服务端返回应答消息,通信框架负责反序列化等。
- I/O 线程将应答设置到 Future 对象的操作结果中。
- Future 对象扫描注册的监听器列表,循环调用监听器的 operationComplete方法,将结果通知给监听器,监听器获取到结果,执行后续业务,异步调用结束。
还有一种异步调用形式,就是不添加 Listener,用户连续发起 N次服务调用,然后依次从 RPC上下文中获取 Futrue对象,最终再主动 get结果,业务线程阻塞,相对比老的同步服务调用,它的阻塞时间更短,工作原理如下: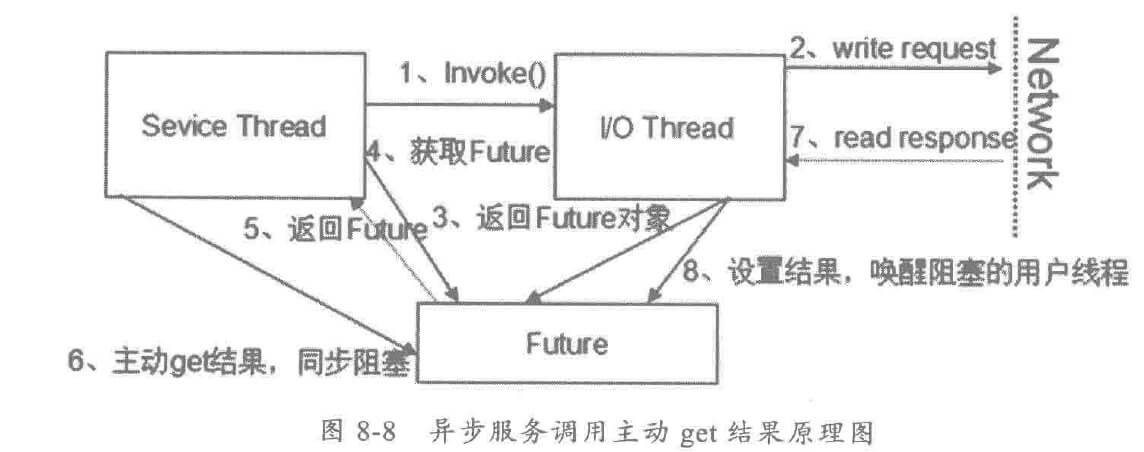
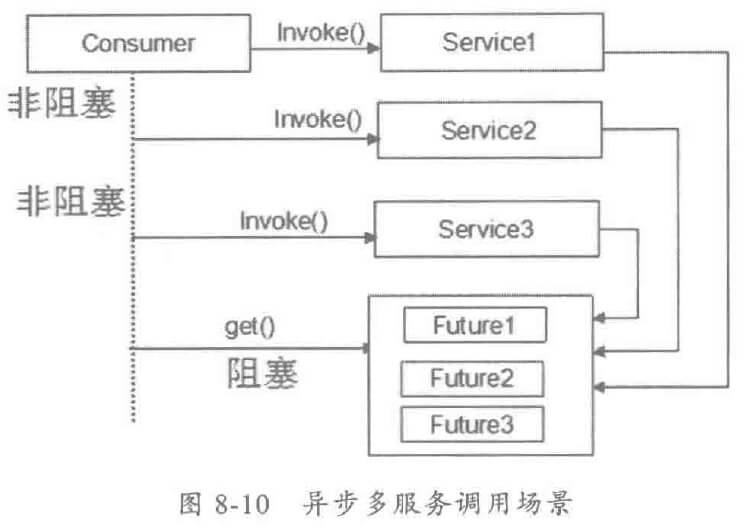
其串行到并行的优化原理如下图: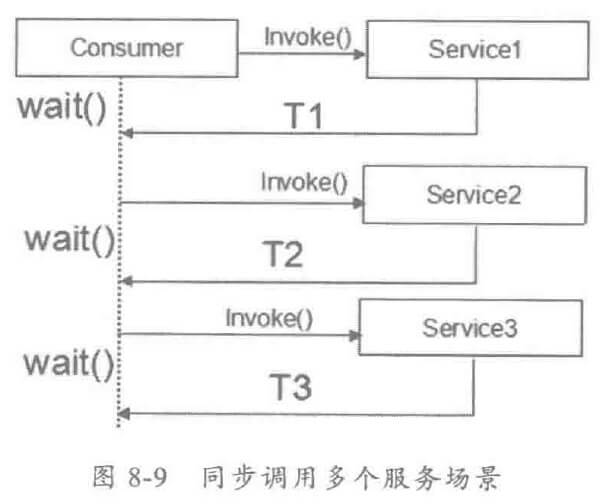
异步服务调用的代码示例如下:1
2
3
4
5
6XxxService1.xxxMethod(Req); // 立即返回 null
Future f1 = RpcContext.getContext().getFuture();
XxxService2.xxxMethod(Req);
Future f2 = RpcContext.getContext().getFuture();
Object xResult1 = f1.get(3000);
Object xResult2 = f2.get(3000);
第二种基于 Future-Listener 的纯异步服务调用示例如下:1
2
3
4XxxService1.xxxMethod(Req);
Future f1 = RpcContext.getContext().getFuture();
Listener l = new Listener();
f1.addListener(l);
2.3 并行服务调用
A服务->B服务->C服务->…
串行服务调用比较简单,但在一些业务场景中,需要采用并行服务调用来降低 E2E 的时延。
- 多个服务之间逻辑不存在互相依赖关系,执行先后顺序没有严格的要求,逻辑上可以被并行执行。
- 长流程业务,调用多个服务,对时延比较敏感,其中有部分服务逻辑上无上下文关联。
目标主要有两个: - 降低业务 E2E 时延。
- 提升整个系统的吞吐量。
2.4 泛化调用
主要用于客户端没有API 接口及数据模型的场景,使用 Map表示。
3 最佳实践
服务框架支持多种服务调用方式,在实现项目中中如何选择,建议从以下几个角度考虑:
- 降低业务 E2E时延:业务调用链是否太长、某些服务是否不太可靠,需要对服务调用流程进行梳理,看是否可以通过并行服务调用来提升调用效率,降低服务调用时延。
- 可靠性角度:某些业务调用链上的关键服务不太可靠,一旦出故障会导致大量线程资源被挂住,可以考虑使用异步服务调用防止故障扩展。
- 业务场景:对于测试,不想为每个测试用例都开发一个服务接口,能否做一个通用的测试框架,通过 Map等泛容器实现通用服务调用。
- 传统的 RPC调用:服务调用比较简单,对时延要求不高的场景,可以考虑同步服务调用。
4 个人总结
服务调用有多种形式,需要从业务和技术做出取舍。