2019/02周总结
除非你觉得你的时间不是很宝贵,否则不要看这篇流水账式的博文,这只是篇个人的工作的学习一个总结而已,没有包含任何的技术细节

在多线程环境下,使用 HashMap 进行 put 操作时由于有 resize 存在,因此会有死锁隐患,为了避免这种bug的隐患,强烈建议使用 ConcurrentHashMap 代替 HashMap,为了对更深入的了解,本文将对 JDK1.7 和 JDK1.8 的不同实现进行分析

jcmd 是 JDK1.7 之后出的命令行工具,如果你是 JDK1.7 之后的项目,建议你用 jcmd 替换掉 jps。
你可以使用它来查看堆信息:jcmd pid GC.heap_dump
也可以用来查看当前所有的 VM 虚拟机:jcmd -l
以及还有当前 VM 虚拟机的参数信息:jcmd PID VM.flags
具体更多命令:jcmd help jcmd PID help


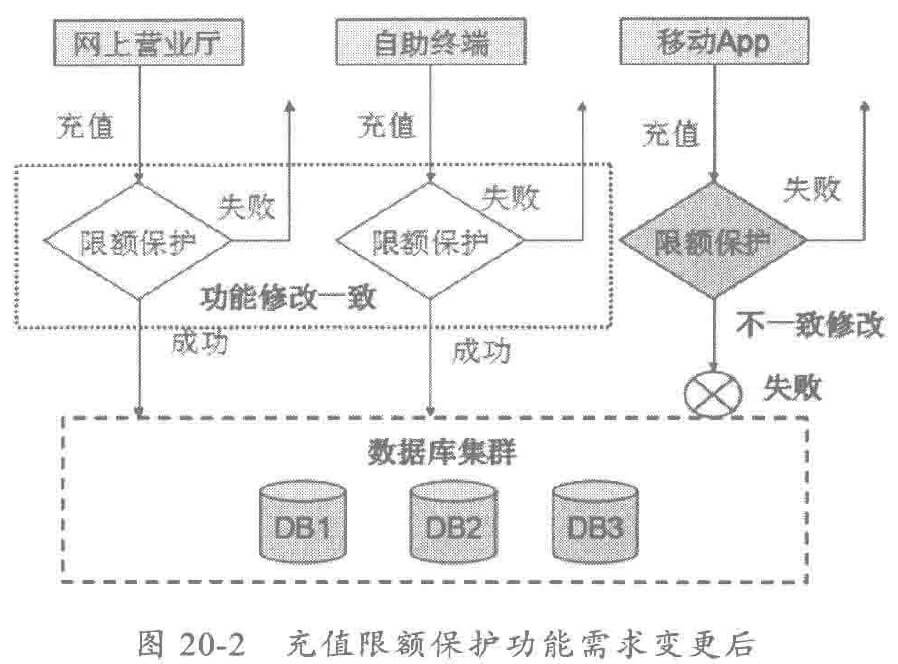
代码重复率变高之后,已有功能变更或者新需求加入都会非常困难,以充值缴费功能为例,不同的充值渠道开发了相同的限额保护功能,当限额保护功能发生变更之后,所有重复开发的限额保护功能都需要重新修改和测试,很容易出现修改不一致或者被遗漏,导致部分渠道充值功能正常: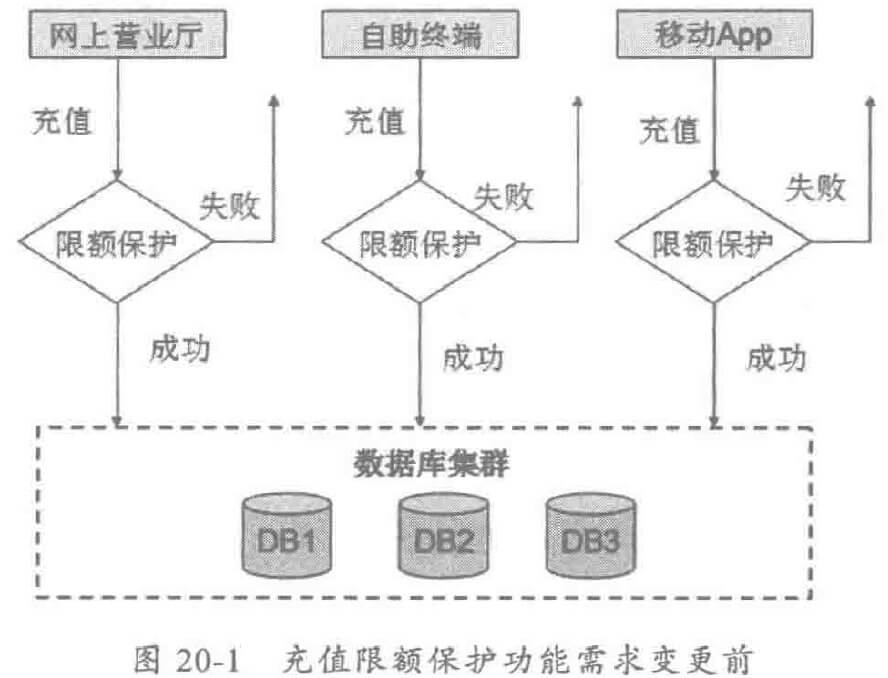
传统的业务流程是由一长串本地接口或者方法调用串联起来的,而且往往由一个负责开发和维护。随着业务的发展和需求变化,本地diamante在不断地迭代和变更,最后形成了一个个垂直的功能孤岛,只有原来的开发者才理解接口调用关系和功能需求,一旦原来的开发者离职或调到其它项目组,这些功能模块的运维就会变得非常困难: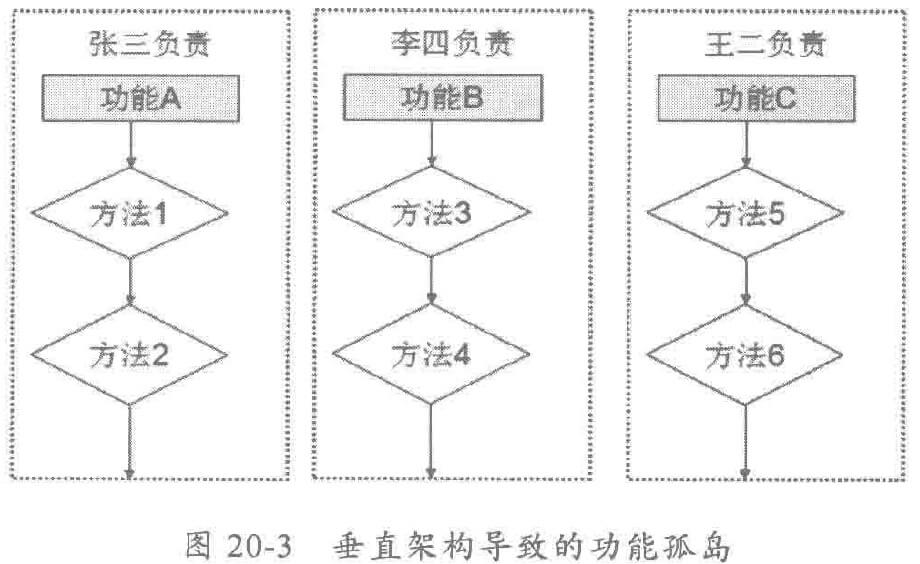
微服务化之前,一个大型的应用系统通常会包含多个子应用,不同应用之间存在很多重复的公共代码,所有应用共用一套数据库,架构图如下: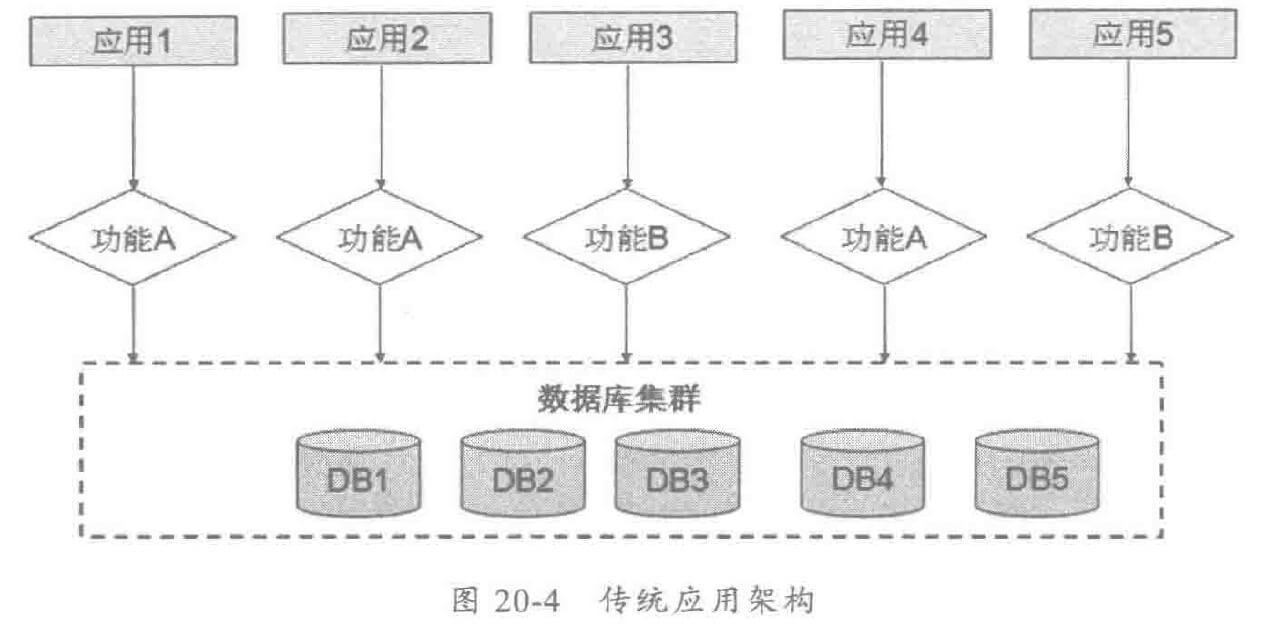
将功能A 和功能B 服务化之后,应用作为消费者直接调用服务A 和服务B ,这样就实现了对原有重复代码的收编,同时系统之间的调用关系也更加清晰,如下图: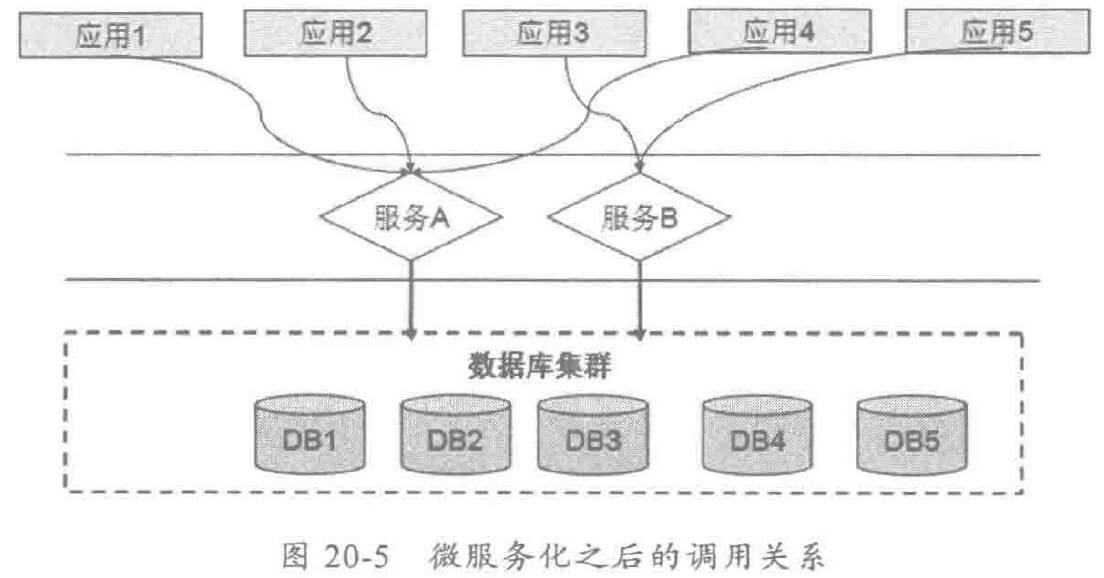
基于服务注册中心的定于发布机制,实现服务消费者和提供者之间的解耦。
将核心业务抽取出来,作为独立的服务,逐渐形成稳定的底层微服务。
应用的拆分分为水平拆分和垂直拆分两种,水平拆分以业务领域为维度,抽象出几个不同的业务域,每个业务域作为一个独立的服务中心对外提供服务。领域服务可以独立地伸缩和升级,快速地响应需求变化,同时与其它业务领域解耦。原理图如下: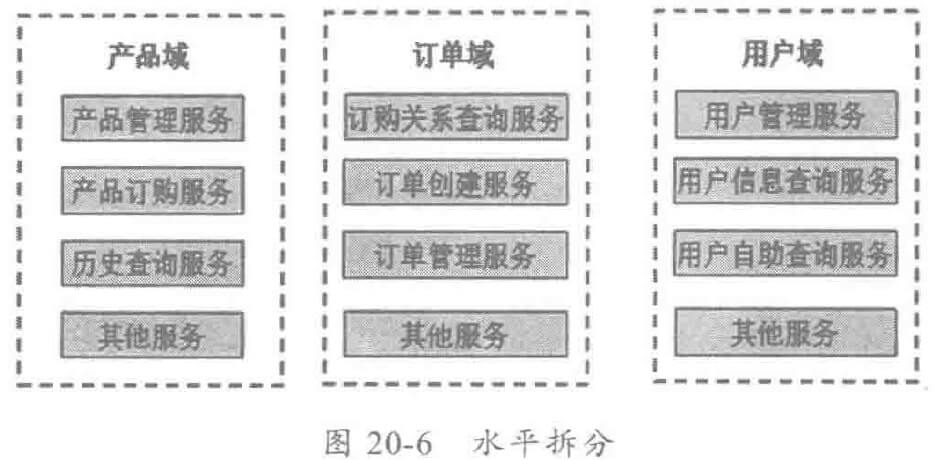
应用的垂直拆分主要包括前后台逻辑拆分、业务逻辑和数据访问层拆分,拆分之后的效果图如下: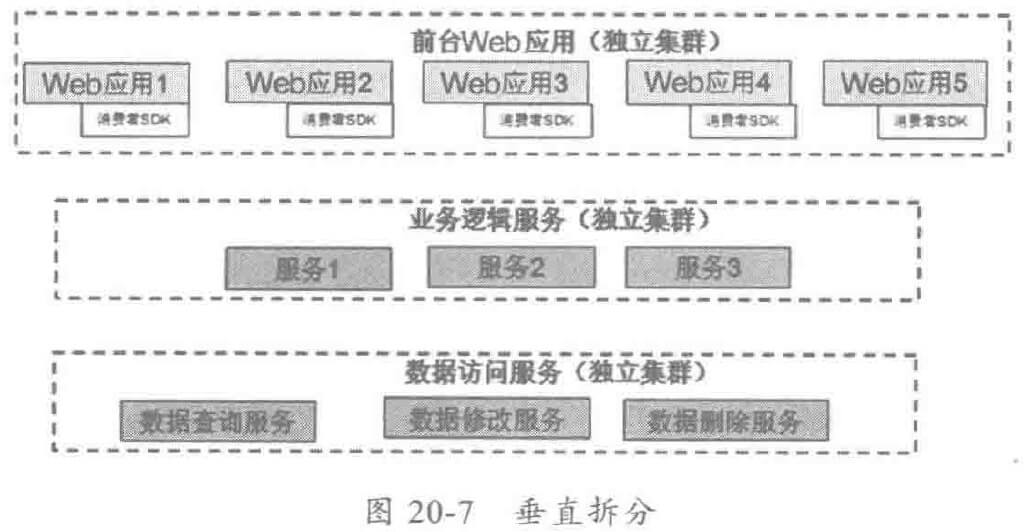
敏捷性的产生,是将运行中的系统解耦为一系列功能单一服务的结果。微服务架构能够对系统中其它部分的依赖加以限制,这种特性能够让基于微服务架构的应用在应对 BUG 或是对新特性需求时,能够快速地进行变更。而传统的垂直架构:“要对应用程序中某个小部分进行变更,就必须对整体架构进行重新编译和构建,并且重新进行全量部署。”
微服务架构(MSA)是一种架构风格,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。对比图如下: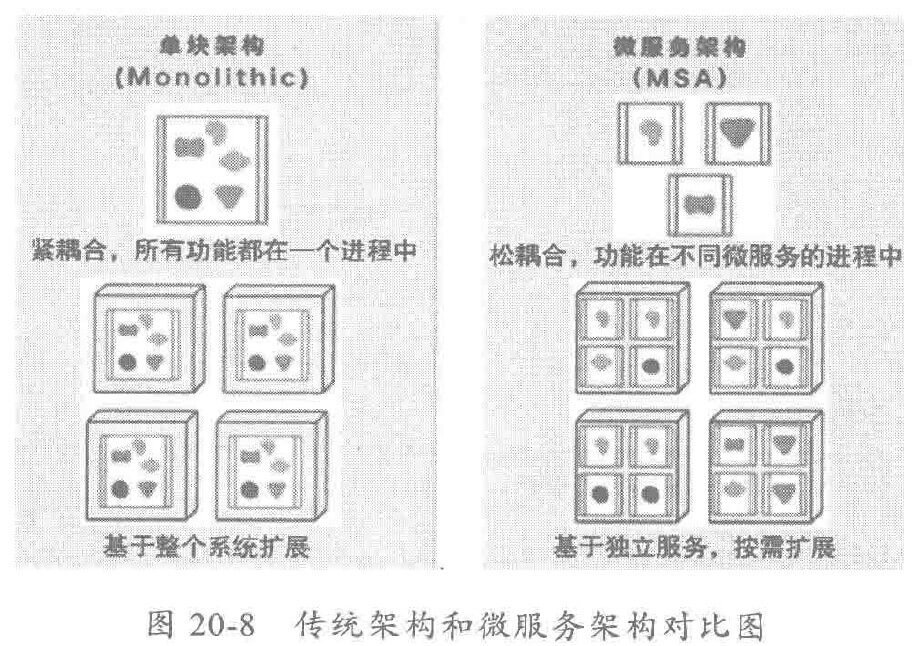
通用的划分原则是:微服务通常是简单、原子的微型服务,它的功能单一,只负责处理一件事,与代码行数并没有直接关系,与需要处理的业务复杂度有关。有些复杂的功能,尽管功能单一,但是代码量可能成百上千行,因此不能以代码量作为划分微服务的维度。
“微”所表达的是一种设计思想和指导方针,是需要团队或者组织共同努力找到的一个平衡点。
对于不同的微服务,虽然实现逻辑不同,但是开发方式、持续集成环境、测试策略和部署机制以及后续的上线运维都是类似的,为了满足 DRY 原则并消除浪费,需要搭建统一的开发打包和持续集成环境。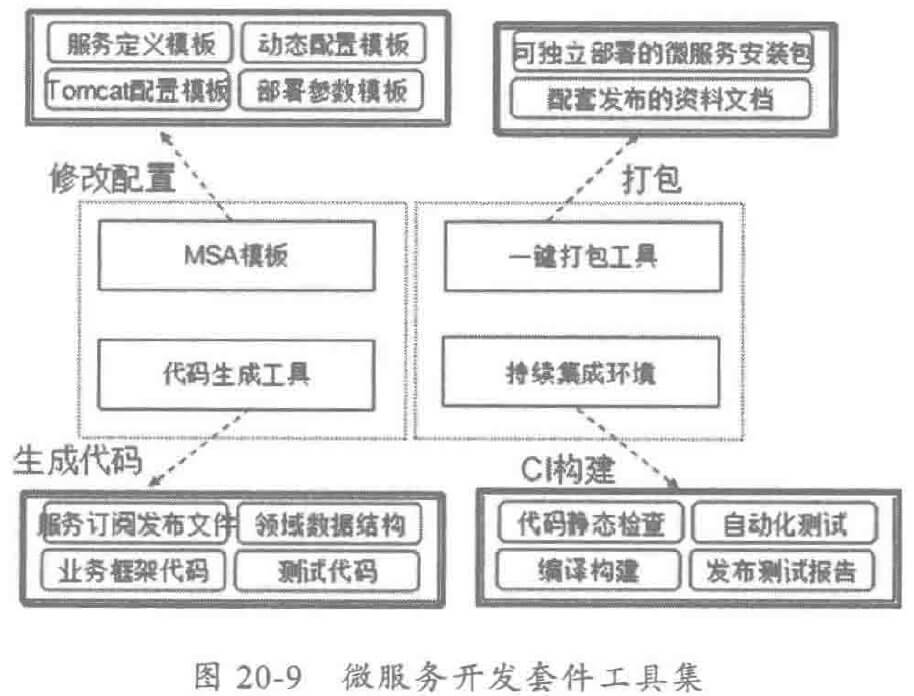
Docker 是一套开源工具,它能够以某种方式对现有的基于容器的虚拟化技术进行封装,使得它能够在更广阔的工程社区中得到应用,主要在于快速和可移植性。
普通的虚拟机在每次开机时都需要启动一个完整的新操作系统实例,而 Docker 容器能够通过内核共享的方式,共享一套托管操作系统。这意味着,Docker 容器的启动和停止只需要几百毫秒。这样就有更高的敏捷性。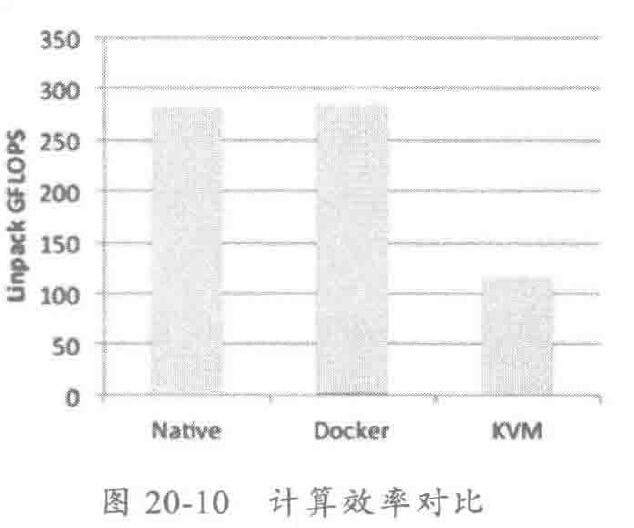
物理机 VS Docker VS 虚拟机
微服务架构对运维和部署流水线要求非常高,服务拆分的粒度越细,运维和治理成本就越高,挑战总结如下:
解决微服务运维的主要措施就是:分布式和自动化。利用分布式系统的性能线性增长和弹性扩容能力,支撑大规模微服务对运维系统带来的性能冲击,包括:
因此优点如下:
微服务涉及到了组织架构、涉及、交付、运维等方面的变革,核心目标是为了解决系统的交付周期,降低维护成本和研发成本。
但是带来了运维成本、服务管理成本等。
不可脱离业务实际而强制使用微服务。
相对于传统的本地 Java API 调用,跨进程的分布式服务调用面临的故障风险更高:
对于应用而言,分布式服务框架需要具备足够的健壮性,在平台底层能够拦截并向上屏蔽故障,业务只需要配置容错策略,即可实现高可靠性。
在分布式服务调用时,某个服务提供者可能已经宕机,如果采用随机路由策略,消息会继续发送给已经宕机的服务提供者,导致消息发送失败。为了保证路由的正确性,消费者需要能够实时获取服务提供者的状态,当某个服务提供者不可用时,将它从缓存的路由表中删除掉,不再向其发送消息,直到对方恢复正常。
以 ZooKeeper 为例,ZooKeeper 服务端利用与 ZooKeeper 客户端之间的长链接会话做心跳检测。
分布式服务框架的服务消费者和提供者之间默认往往采用长链接,并且通过双向心跳检测保障链路的可靠性。
在一些特殊的场景中,服务提供者和注册中心之间网络可达,服务消费者和注册中心网络也可达,但是服务提供者和消费者之间网络不可达,或者服务提供者和消费者之间链路已经断连。此时,服务注册中心并不能检测到服务提供者异常,但是如果消费者仍旧向链路中断的提供者发送消息,写操作将会失败。
为了解决该问题,通常需要使用服务注册中心检测 + 服务提供者和消费者之间的链路有效性检测双重检测来保障系统的可靠性,它工作原理如下: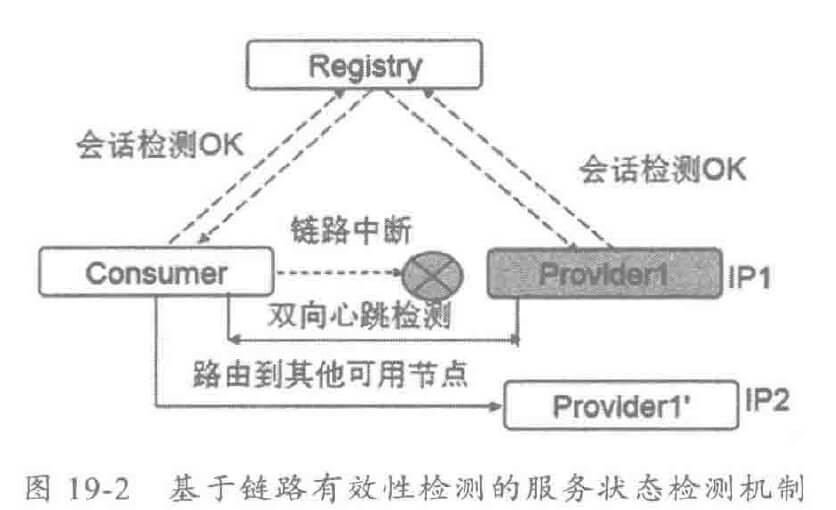
当消费者通过双向心跳检测发现链路故障之后,会主动释放链接,并将对应的服务提供者从路由缓存表中删除。当链路恢复之后,重新将恢复的故障服务提供者地址信息加入地址缓存表中。
在集群组网环境下,由于硬件性能差异、各服务提供者的负载不均等原因,如果采用随机路由分发策略,会导致负载较重的服务提供者不堪重负被压垮。
利用服务的健康度监测,可以对集群的所有服务实例进行体检,根据体检加过对健康度做打分,得分较低的亚健康服务节点,路由权重会被自动调低,发送到对应节点的消息会少很多。这样实现“能者多劳、按需分配”,实现更合理的资源分配和路由调度。
服务的健康度监测通常需要采集如下性能 KPI 指标:
原理如下: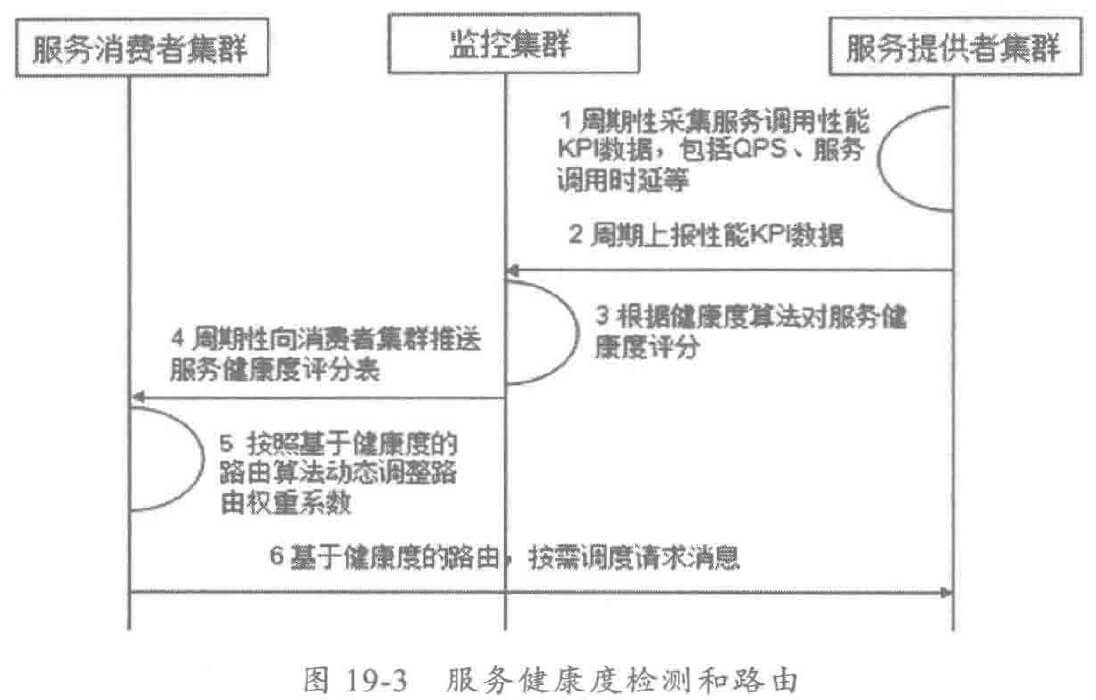
分为四个层次:
个人理解为线程级。即通过将服务部署到不同的线程池实现故障隔离。对于订单、购物车等核心服务可以独立部署到一个线程池中,与其它服务做线程调度隔离。对于非核心服务,可以合设共享同一个/多个线程池,防止因为服务数过多导致线程数过度膨胀。
服务发布的时候,可以指定服务发布到哪个线程池中,分布式服务框架拦截 Spring 容器的启动,解析 XML 标签,生成服务和线程池的映射关系,通信框架将解码后的消息投递到后端时,根据服务名选择对应的线程池,将消息投递到映射线程池的消息队列中。
原理图如下: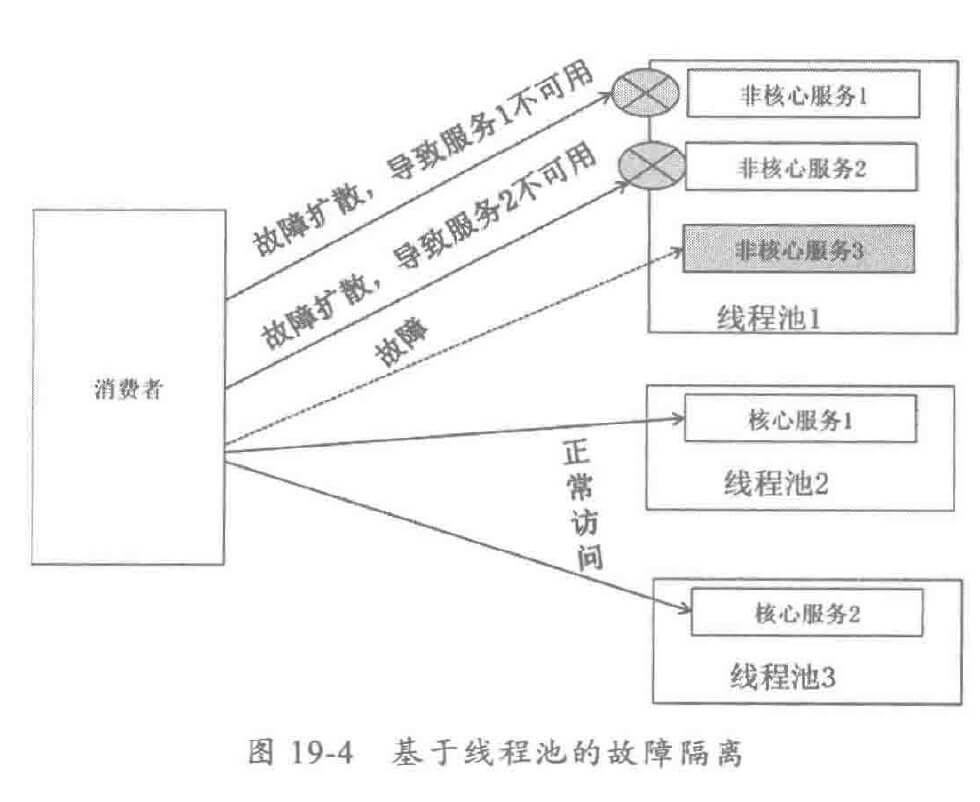
如果故障服务发生了内存泄漏异常,它会导致整个进程不可用。
将基础设施层虚拟化、服务化,将应用部署到不同的 VM 中,利用 VM 对资源层的隔离,实现高层次的服务故障隔离,工作原理如下: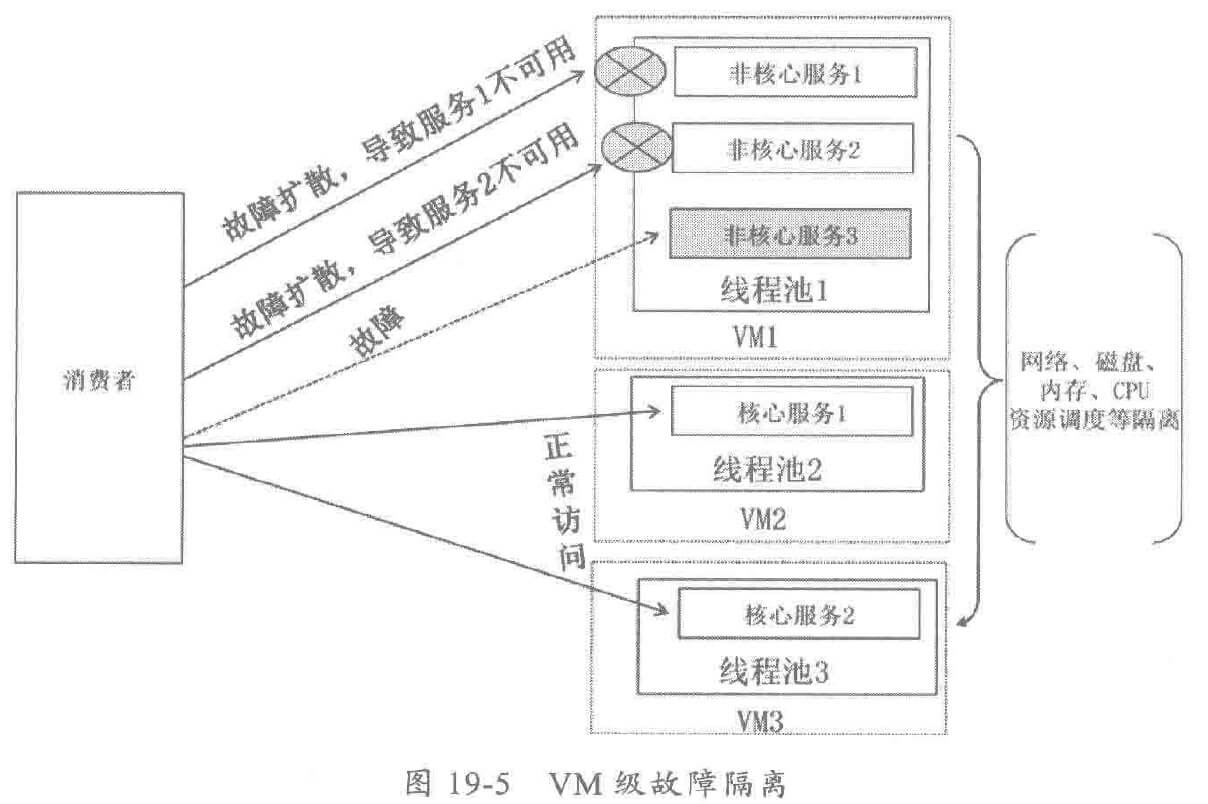
当组网规模足够大、硬件足够多的时候,硬件的故障就由小概率事件转变为普通事件。如何保证在物理机故障时,应用能够正常工作,是一个不小的挑战。
利用分布式服务框架的集群容错功能,可以实现位置无关的自动容错,工作原理如下: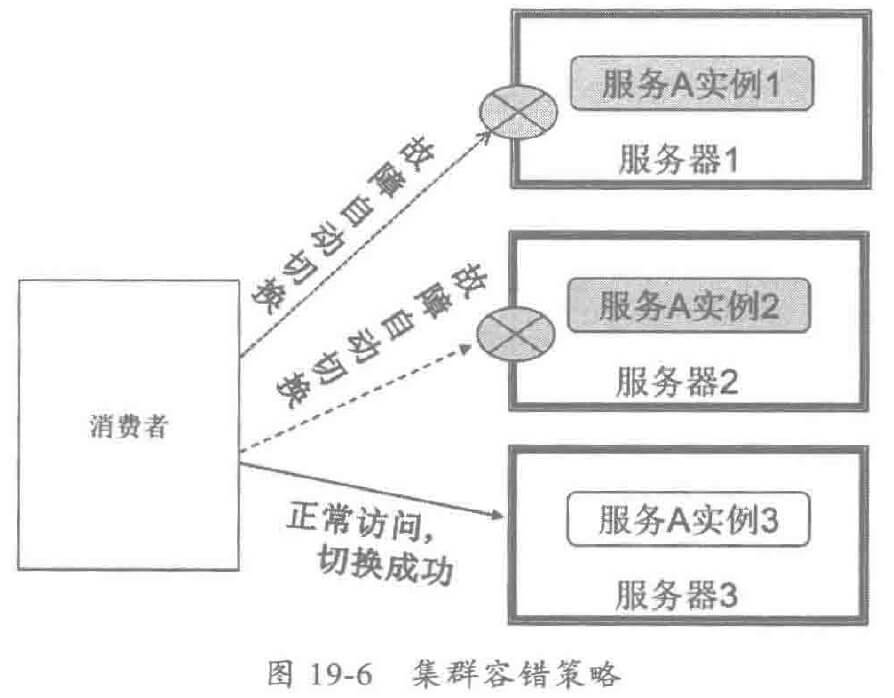
如果要保证当前服务器宕机时不影响部署在上面运行的服务,需要采用分布式集群部署,而且要采用非亲和性安装:即服务实例需要部署到不同的物理机上,通常至少需要 3 台物理机,假如单台物理机的故障发生概率为 0.1 %,则 3 台同时发生故障的概率为 0.001%,服务的可靠性将会达到 99.999%,完全可以满足大多数应用场景的可靠性要求。
物理机故障重启之后,通过扩展插件通知 Watch Dog 重新将应用拉起,应用启动时会重新发布服务,服务发布成功之后,故障服务器节点就能重新恢复正常工作。 ·`
同城容灾时,都需要使用多个机房,下面针对跨机房的容灾和故障隔离方案进行探讨。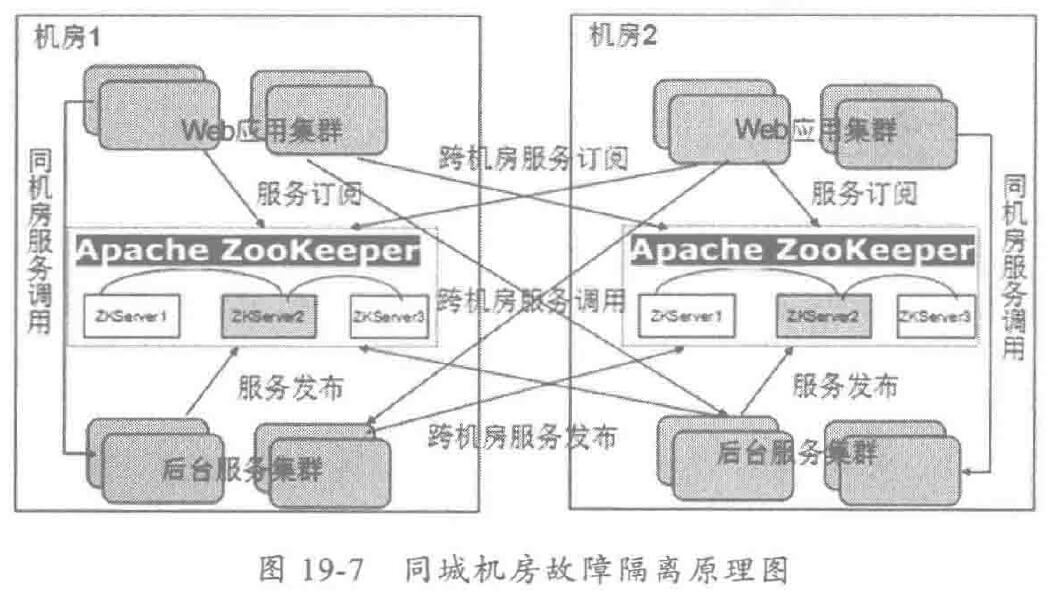
机房1 和机房2 对等部署了2套应用集群,每个机房部署一套服务注册中心集群,服务订阅和发布同时针对两个注册中心,对于机房1 或者机房2 的 Web 应用,可以同时看到两个机房的服务提供者列表。
理由时,优先访问同一个机房的服务提供者,当本机房的服务提供者大面积不可用或者全部不可用时,根据跨机房路由策略,访问另一个机房的服务提供者,待本机房服务提供者集群恢复到正常状态之后,重新切换到本机房访问模式。
当整个机房宕机之后,由前端的 SLB\F5 负载均衡器自动将流量切换到容灾机房,由于主机房整个瘫掉了,容灾机房的消费者通过服务状态监测将主机房的所有服务提供者从路由缓存表中删除,服务调用会自动切换到本机房调用模式,实现故障的自动容灾切换。
上面的方案需要分布式服务框架支持多注册中心,同一个服务实例,可以同时注册到多个服务注册中心中,实现跨机房的服务调用。两个机房共用一套服务注册中心也可以,但是如果服务注册中心所在的机房整个宕掉,则分布式服务框架的服务注册中心将不可用。已有的服务调用不受影响,新的依赖服务注册中心的操作江辉失败,例如服务治理、运行期参数调整、服务的状态监测等功能将不可用。
服务注册中心需要采用对等集群设计,任意一台宕机之后,需要能够自动切换到下一台可用的注册中心。例如 ZooKeeper ,如果某个 Leader 节点宕机,通过选举算法会重新选举出一个新的 Leader,只要集群组网实例数不小于 3,整个集群就能够正常工作。
监控中心集群宕机之后,只丢失部分采样数据,依赖性能 KPI 采样数据的服务健康度监测功能不能正常使用,服务提供者和消费者依然能够正常运行,业务不会中断。
某个服务提供者宕机之后,利用集群容错策略,会舱室不同的容错恢复手段,例如使用 FailOver 容错策略,自动切换到下一个可用的服务,直到找到可用的服务为止。
如果整个服务提供者集群都宕机,可以利用服务放通、故障引流、容灾切换等手段。
任何假设的宕机情况都会出现,解决手段不外乎:
关于 ZooKeeper实现分布式锁,笔者在武汉小米一面(结果挂了)被问到过,因此记录如下。
以下的理论知识源自《 从Paxos到Zookeeper分布式一致性原理与实践 》第六章,代码 完全根据书本理论进行实现,并且经多线程测试,在正常情况可行。
源码:https://github.com/LiWenGu/MySourceCode/tree/master/example/src/main/java/com/lwg/zk_project
核心点:
抢占式创建相同名称的临时节点,谁成功创建节点,则代表谁获得了锁。原书流程图: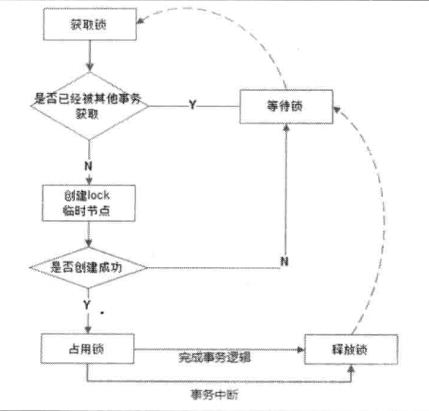
我自己理解的流程: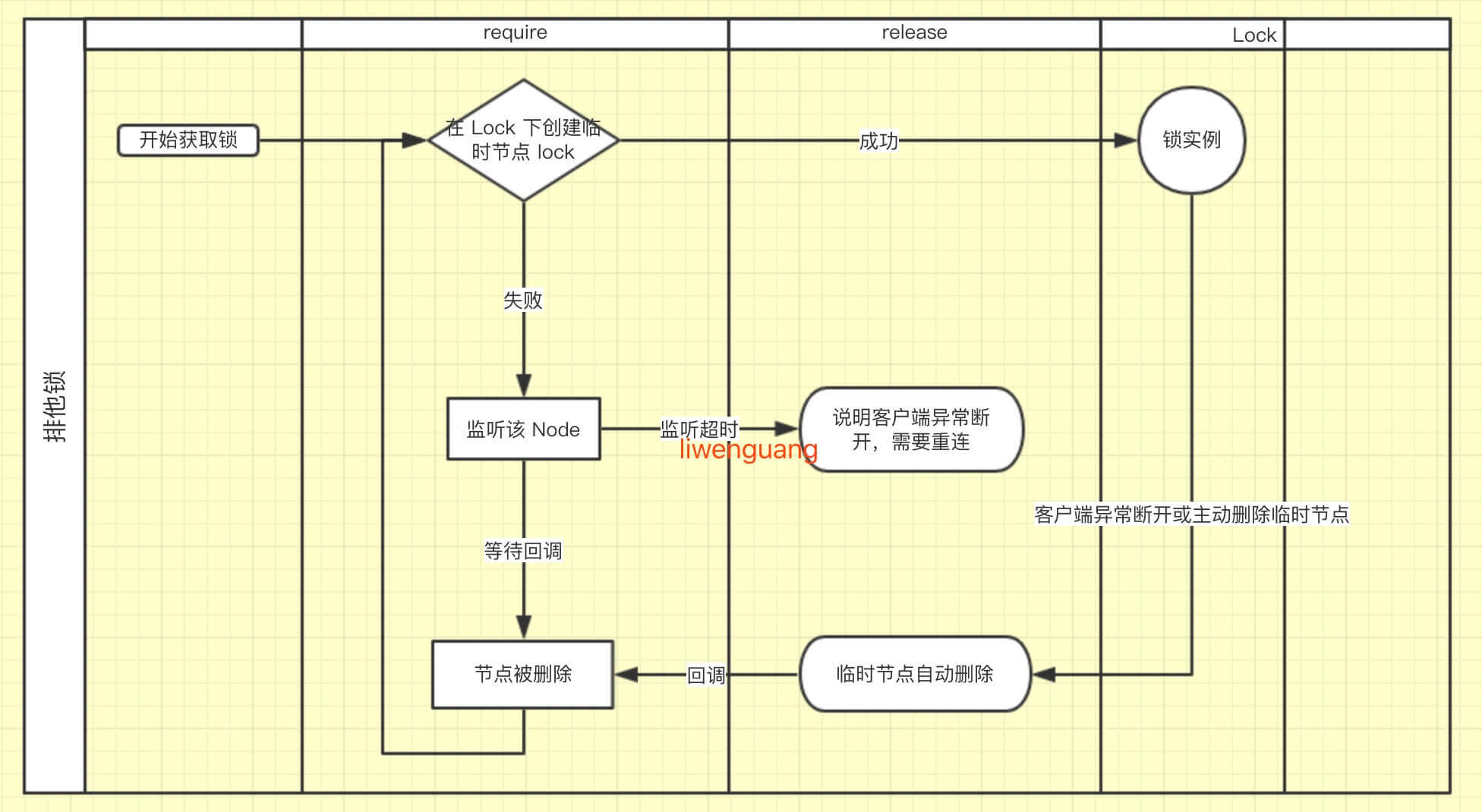
统一接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33/**
* @Author liwenguang
* @Date 2018/6/15 下午9:16
* @Description
*/
public interface DistributedLock {
/**
* @Author liwenguang
* @Date 2018/6/15 下午9:17
* @Description 获取锁,默认等待时间
*/
default void tryRead() throws ZkException { throw new RuntimeException("子类不支持"); }
/**
* @Author liwenguang
* @Date 2018/6/15 下午9:18
* @Description 获取锁,指定超时时间
*/
default void tryRead(long time, TimeUnit unit) { throw new RuntimeException("子类不支持"); }
void tryWrite() throws ZkException;
default void tryWrite(long time, TimeUnit unit) { throw new RuntimeException("子类不支持"); }
/**
* @Author liwenguang
* @Date 2018/6/15 下午9:18
* @Description 释放锁
*/
void release() throws ZkException;
}
核心代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45private void tryGetLock() {
CountDownLatch countDownLatch = new CountDownLatch(1);
while (true) {
try {
zkClient.createEphemeral(EXCLUSIVE_LOCK_NAMESPACE + lockPath);
log.info(Thread.currentThread().getName() + "获取锁成功");
break;
} catch (ZkNodeExistsException e) {
// log.warn(Thread.currentThread().getName() + "获取锁失败");
if (zkClient.exists(EXCLUSIVE_LOCK_NAMESPACE + lockPath)) {
MyIZkDataListener myIZkChildListener = new MyIZkDataListener(countDownLatch);
zkClient.subscribeDataChanges(EXCLUSIVE_LOCK_NAMESPACE + lockPath, myIZkChildListener);
} else {
countDownLatch.countDown();
}
}
try {
// 这里需要阻塞式通知,因此使用 countDownLatch实现
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.info("获取到了锁");
}
class MyIZkDataListener implements IZkDataListener {
private CountDownLatch countDownLatch;
public MyIZkDataListener(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
public void handleDataChange(String dataPath, Object data) throws Exception { }
public void handleDataDeleted(String dataPath) throws Exception {
//log.info(Thread.currentThread().getName() + "被回调了");
zkClient.unsubscribeDataChanges(EXCLUSIVE_LOCK_NAMESPACE + lockPath, this);
countDownLatch.countDown();
}
}
核心点:
顺序临时节点,只看后缀的数字我们可以理解为 一种从小到大的队列(例:我们在做订单请求的时候,对订单A做创建->
支付-> 完成三个操作,对应 ZK节点则节点A下有三个子节点,这时候节点A可以理解为一个队列)。
原书流程图: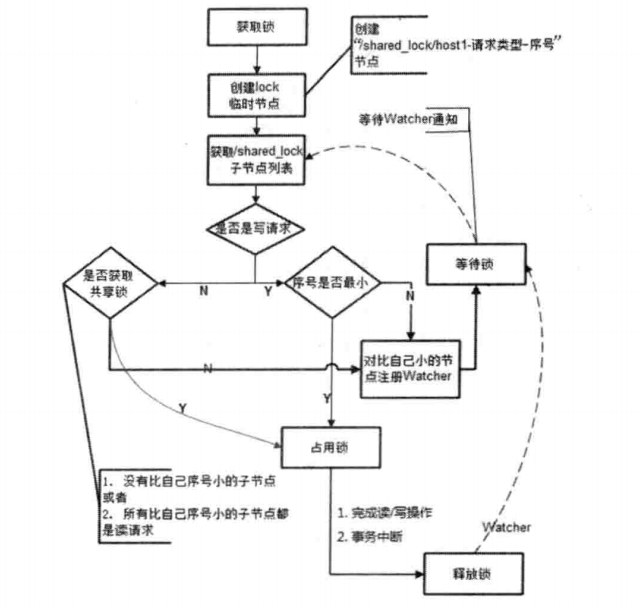
我自己理解的流程:
核心代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
public void tryRead() throws ZkException {
if (!zkClient.exists(SHARED_LOCK_NAMESPACE + lockPath)) {
zkClient.createPersistent(SHARED_LOCK_NAMESPACE + lockPath);
}
CountDownLatch countDownLatch = new CountDownLatch(1);
curNode = zkClient.createEphemeralSequential(SHARED_LOCK_NAMESPACE + lockPath + "/" + SHARED_READ_PRE, null);
String curSequence = curNode.split(SHARED_READ_PRE)[1];
log.info(curSequence + "创建读锁-R");
while (true) {
List<String> children = zkClient.getChildren(SHARED_LOCK_NAMESPACE + lockPath);
// 记录序号比自己小的写请求
List<String> writers = new ArrayList<>();
for (String brother : children) {
if (brother.startsWith(SHARED_WRITE_PRE)) {
String sequence = brother.split(SHARED_WRITE_PRE)[1];
if (curSequence.compareTo(sequence) > 0) {
writers.add(brother);
}
}
}
if (writers.isEmpty()) {
// 没有比自己序号小的写请求,说明自己获取到了读锁
//log.info(Thread.currentThread().getName() + "没有比自己序号小的写请求-R");
break;
} else {
// 获取最近的那个写锁
String lastWriter = SHARED_LOCK_NAMESPACE + lockPath + "/" + writers.get(writers.size() - 1);
// 判断最近的那个写锁期间是否已经释放了
if (zkClient.exists(lastWriter)) {
MyReadIZkChildListener myReadIZkChildListener = new MyReadIZkChildListener(lastWriter, countDownLatch);
zkClient.subscribeDataChanges(lastWriter, myReadIZkChildListener);
} else {
countDownLatch.countDown();
}
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.info("获取到了锁-R");
}
class MyReadIZkChildListener implements IZkDataListener {
private String lastWriter;
private CountDownLatch countDownLatch;
public MyReadIZkChildListener(String lastWriter, CountDownLatch countDownLatch) {
this.lastWriter = lastWriter;
this.countDownLatch = countDownLatch;
}
public void handleDataChange(String dataPath, Object data) throws Exception { }
public void handleDataDeleted(String dataPath) throws Exception {
//log.info(Thread.currentThread().getName() + "比自己序号小的那个写请求被释放了-R");
zkClient.unsubscribeDataChanges(lastWriter, this);
// 最近的那个写锁被释放了,但是不排除释放过程中,有其它写锁新加入,因此读锁需要重新获取列表
countDownLatch.countDown();
}
}
public void tryWrite() throws ZkException {
CountDownLatch countDownLatch = new CountDownLatch(1);
if (!zkClient.exists(SHARED_LOCK_NAMESPACE + lockPath)) {
zkClient.createPersistent(SHARED_LOCK_NAMESPACE + lockPath);
}
curNode = zkClient.createEphemeralSequential(SHARED_LOCK_NAMESPACE + lockPath + "/" + SHARED_WRITE_PRE, null);
String curSequence = curNode.split(SHARED_WRITE_PRE)[1];
log.info(curSequence + "创建写锁-W");
while (true) {
List<String> children = zkClient.getChildren(SHARED_LOCK_NAMESPACE + lockPath);
// 记录序号比自己小的请求
List<String> writersOrReader = new ArrayList<>();
for (String brother : children) {
if (brother.equals(SHARED_WRITE_PRE + curSequence)) {
// 排除自己
continue;
}
String sequence = "";
if (brother.contains(SHARED_WRITE_PRE)) {
sequence = brother.split(SHARED_WRITE_PRE)[1];
} else if (brother.contains(SHARED_READ_PRE)) {
sequence = brother.split(SHARED_READ_PRE)[1];
} else {
// 异常名称节点的处理
}
if (curSequence.compareTo(sequence) > 0) {
writersOrReader.add(brother);
}
}
if (writersOrReader.isEmpty()) {
// 没有比自己序号小的请求,说明自己获取到了读锁
//log.info(Thread.currentThread().getName() + "没有比自己序号小的请求-W");
break;
} else {
// 获取最近的那个锁
String lastWriterOrReader = SHARED_LOCK_NAMESPACE + lockPath + "/" + writersOrReader.get(writersOrReader.size() - 1);
// 判断最近的那个锁期间是否已经释放了
if (zkClient.exists(lastWriterOrReader)) {
MyWriteIZkChildListener myWriteIZkChildListener = new MyWriteIZkChildListener(lastWriterOrReader, countDownLatch);
zkClient.subscribeDataChanges(lastWriterOrReader, myWriteIZkChildListener);
} else {
countDownLatch.countDown();
}
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.info("获取到了锁-W");
}
class MyWriteIZkChildListener implements IZkDataListener {
private String lastWriterOrReader;
private CountDownLatch countDownLatch;
public MyWriteIZkChildListener(String lastWriterOrReader, CountDownLatch countDownLatch) {
this.lastWriterOrReader = lastWriterOrReader;
this.countDownLatch = countDownLatch;
}
public void handleDataChange(String dataPath, Object data) throws Exception {
}
public void handleDataDeleted(String dataPath) throws Exception {
//log.info(Thread.currentThread().getName() + "比自己序号小的那个请求被释放了,循环-W");
zkClient.unsubscribeDataChanges(lastWriterOrReader, this);
countDownLatch.countDown();
}
}
readlock
随着业务分布式架构的发展,系统间的系统调用日趋复杂,以电商的商品购买为例,前台界面的购买操作设计到底层上百次服务调用,涉及到的中间件包括:
如果无法有效清理后端的分布式调用和依赖关系,故障定界将会非常困难。利用分布式消息跟踪系统可以有效解决服务化之后系统面临的运维挑战,提高运维效率。
以下为分布式调用示意图: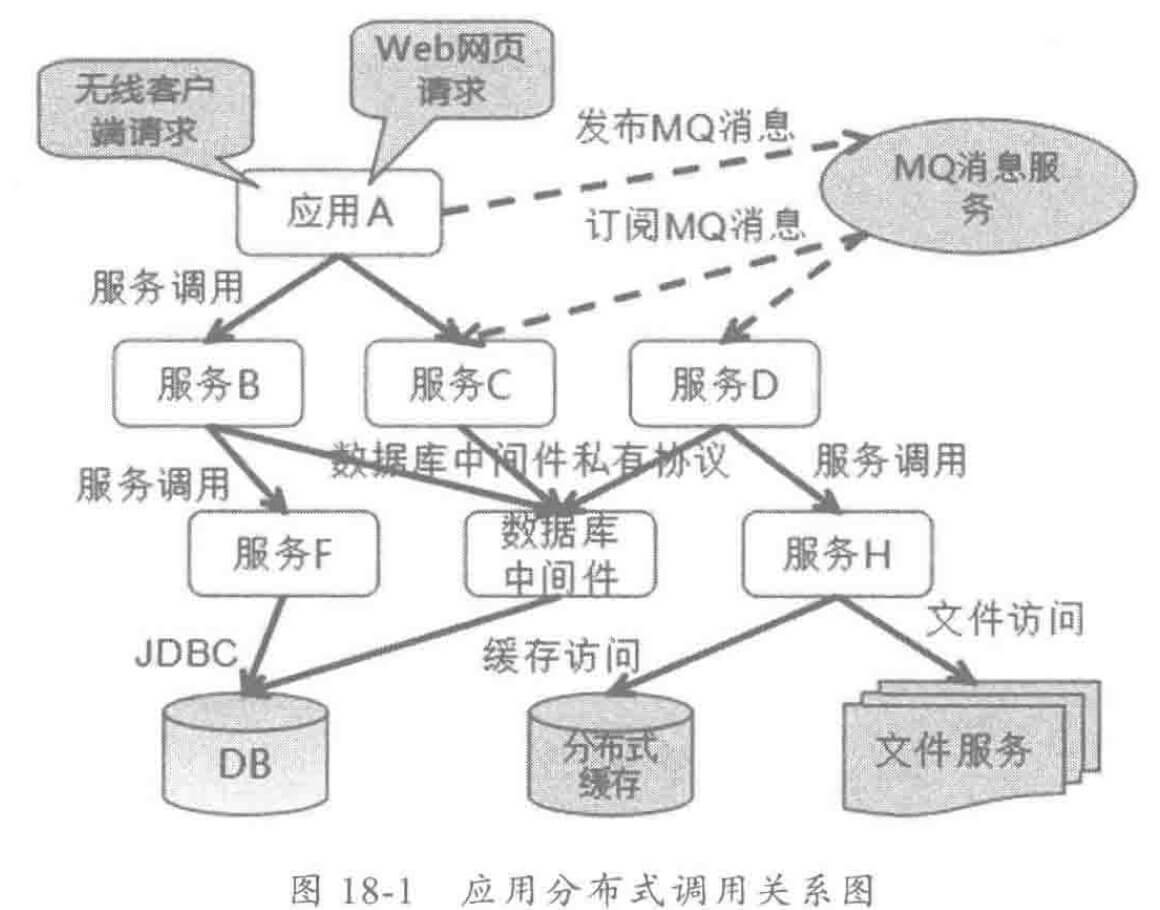
传统应用软件发生故障时,往往通过接口日志手工从故障节点采集日志进行问题分析定位,分布式服务化之后,一次业务调用可能涉及到后台上百次服务调用,每个服务又是集群组网,传统人工到各个服务节点人肉搜索的方式效率很低。
希望能够通过调用链跟踪,将一次业务调用的完整轨迹以调用链的形式展示出来,通过图形化界面查看每次服务调用结果,以及故障信息。
通过在业务日志中增加调用链 ID ,可以实现业务日志和调用链的动态关联。通过调用链进行快速故障定界,然后通过 ID 关联查询,可以快速定位到业务日志相关信息。
通过对调用链调用路径的分析,可以识别应用的关键路径:应用被调用得最多的入口、服务是哪些,找出服务的热点、耗时瓶颈和易故障点。同时为性能优化、容量规划等提供数据支撑。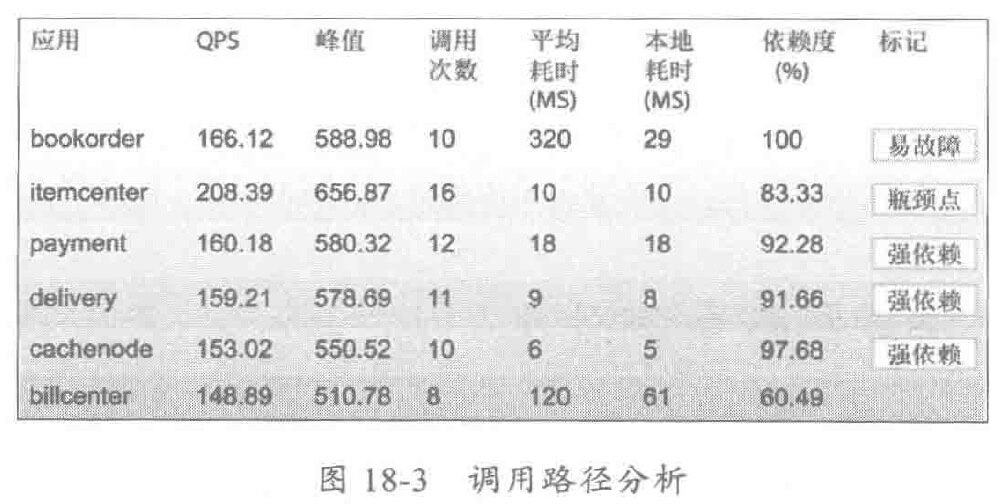
通过调用去向分析,可以对服务的依赖关系进行梳理:
通过对调用来源进行 TOP排序,识别当前服务的消费来源,以及获取各消费者的 QPS、平均时延、出错率等,针对特定的消费者,可以做针对性治理,例如针对某个消费者的限流降级、路由策略修改等,保障服务的 SLA。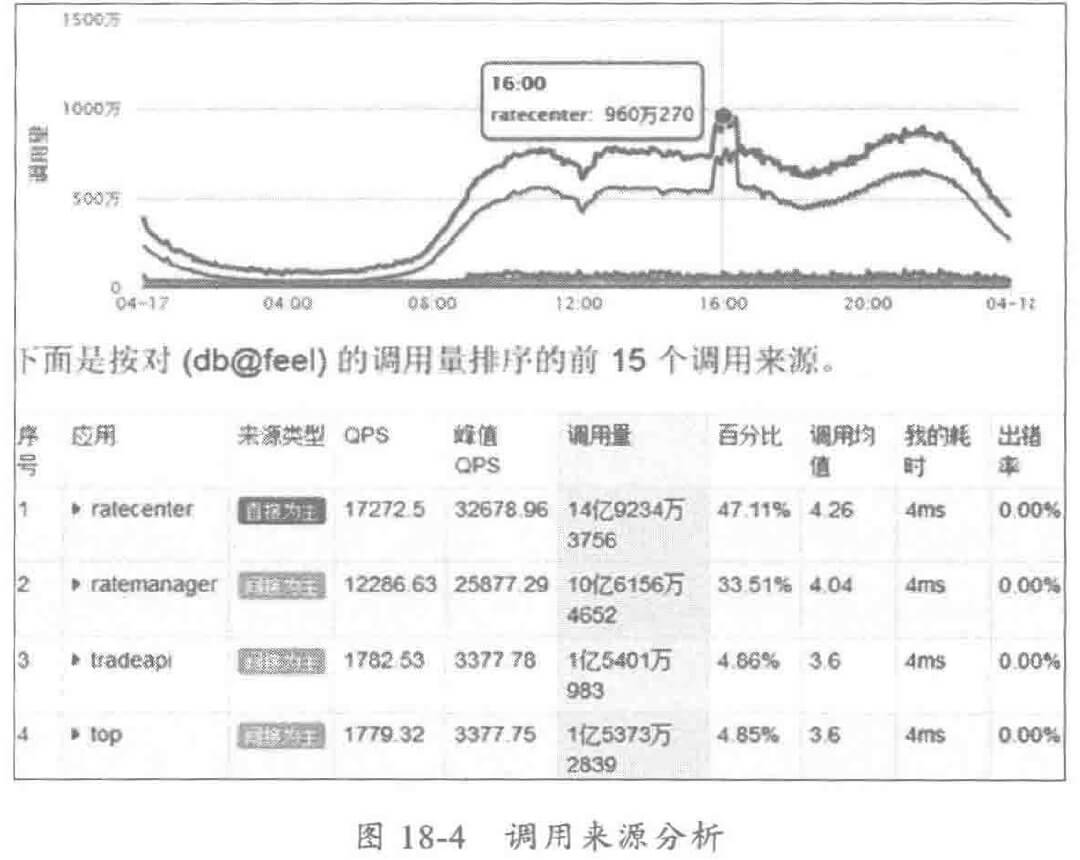
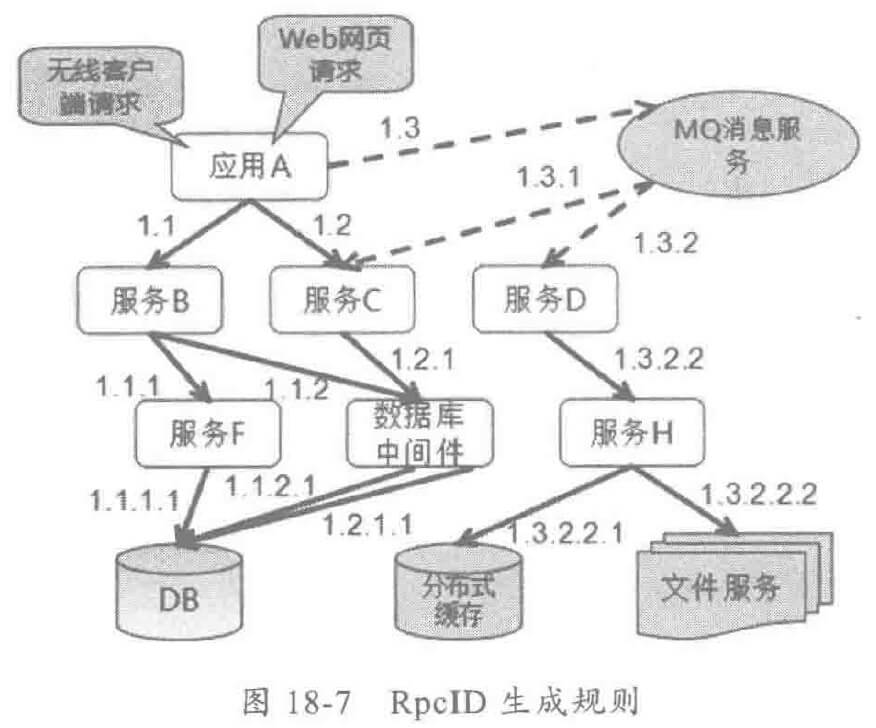
消息跟踪系统的核心就是调用链:每次业务请求都生成一个全局唯一的 TraceID,通过跟踪 ID将不同节点间的日志串接起来,形成一个完整的日志调用链,通过对调用链日志做实时采集、汇总和大数据分析,提取各种维度的价值数据,为系统运维和运营提供大数据支撑。
分布式消息跟踪系统的整体架构如下,由四部分组成: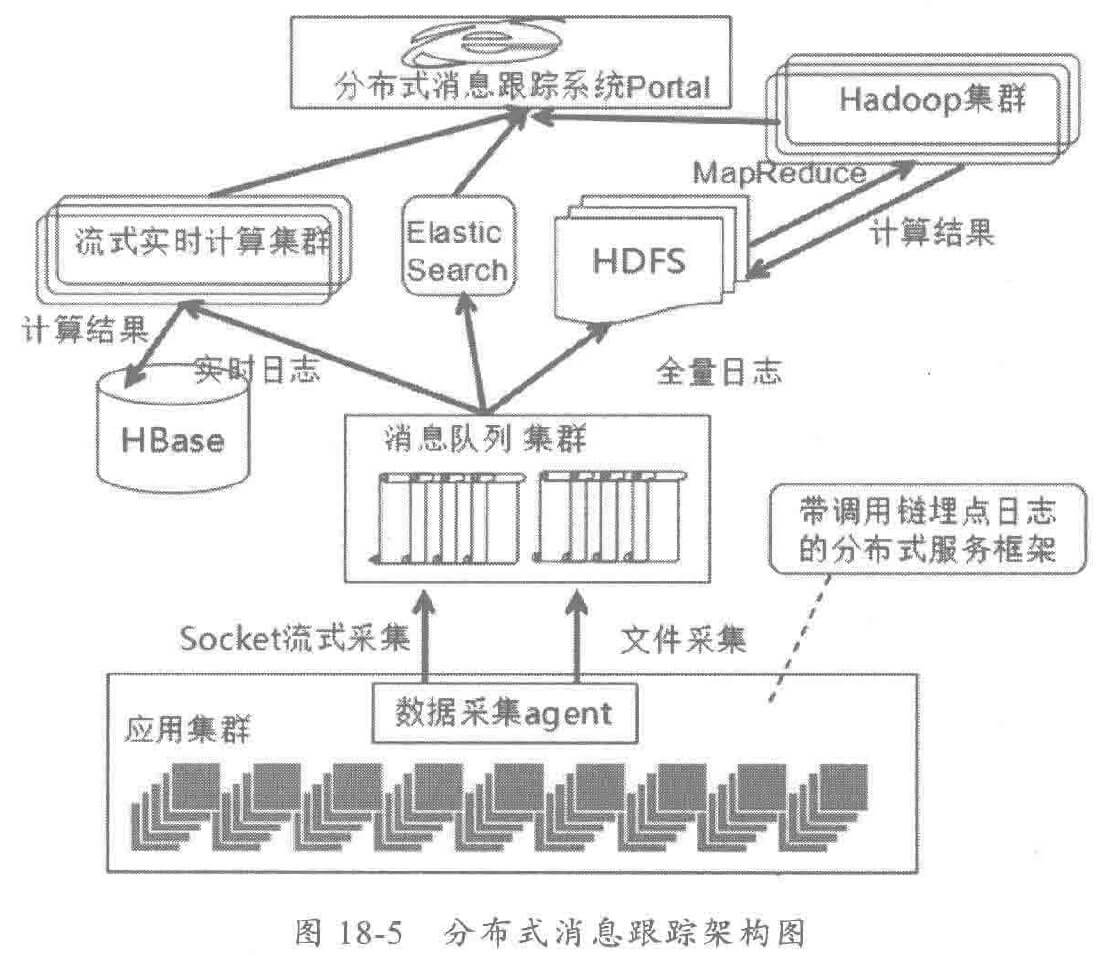
埋点就是分布式消息跟踪系统在当前节点的上下文信息,埋点可以分为两类:
埋点日志的实现,通常会包含如下几个功能:
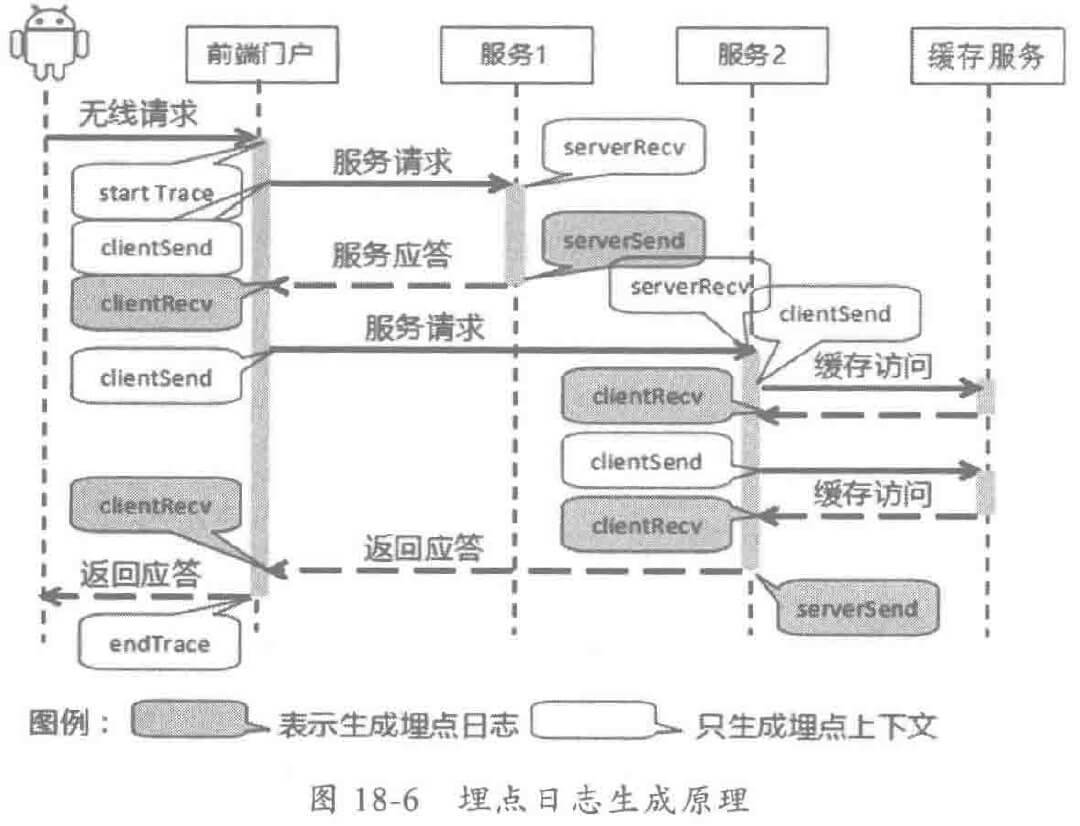
消息跟踪 ID 通常由调用首节点负责生成(各种门户 Portal),本 JVM 之内通常线程上下文传递 TraceID,跨节点传递时,往往通过分布式服务框架的显式传参传递到下游节点,实现消息跟踪上下文的跨节点传递。
埋点日志上下文通常需要包含如下内容:
消息跟踪ID(TraceID)是关联一次完整应用调用的唯一标识,需要在整个集群内唯一,它的取值策略有很多,例如 UUID,UUID(Universally Unique Identifier)即全局唯一标识符,是指在一台机器上生成的数字,它保证对在同一时空中所有机器都是唯一的。按照开发软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片 ID 码和许多可能的数字。由以下几部分组合:当前日期和时间(UUID 的第一部分与时间有关,如果你在生成一个 UUID 之后,过几秒又生成一个 UUID,则第一部分不同,其余相同),时钟序列,全局唯一的 IEEE 机器识别号(如果有网卡,从网卡获得,没有网卡以其它方式获得),UUID 的唯一缺陷在于生成的结果串会比较长。
原理上,埋点日志比较简单,实现起来并不复杂。但是在实际工作中,埋点日志也会面临一些技术挑战,举例如下:
对于线程切换问题,在切换时需求做线程上下文的备份,将埋点上下文复制到切换的线程上下文中,即可解决问题。
频繁写埋点日志影响性能问题,可以通过如下措施改善该问题:
对于高 QPS 的应用,服务调用埋点本身的性能损耗也不容忽视,为了解决 100% 全采样的性能损耗,可以通过采样率来实现埋点低损耗的目标。
采样包括静态采用和动态采样两种,静态采样就是系统上线时设置一个采样率,无论负载高低,均按照采样率执行。动态采样率根据系统的负载可以自动调整,当负载比较低的时候可以实现 100% 全采样,在负载非常重时甚至可以降低到 0 采样。
是否采样由调用链的首节点进行判断,首节点根据采样率算法,决定某个业务访问是否采样,如果需要采样,则把采样标识、TraceID 等采样上下文发送到下游服务节点,下游服务节点根据采样标识做判断,如果采样则获取调用链上下文并补充完整,反之则不埋点。
开源 的 ELK,原理如下: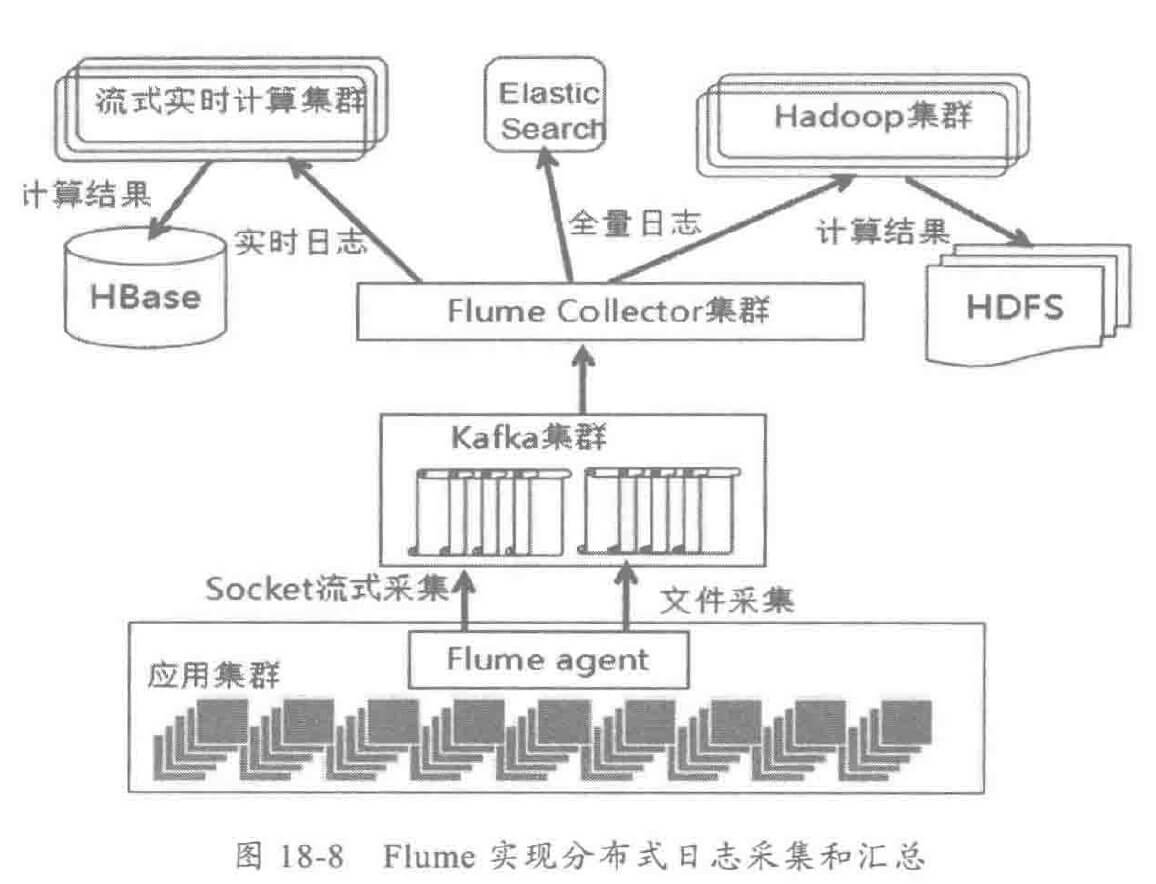
需要考虑:
通过对业务流程的记录和采集,进行在线和离线的大数据计算,数据清洗获取有价值的数据。同时还能根据运行情况做服务的调整。